목차
모바일로 보니 너무 불편해서 수정 좀 했습니다 ㅠㅠ
결과물부터 보자면, kogpt2를 사용해서 슬로건을 생성하였다. 웹으로 서비스를 배포(AWS)하고, 구글애즈로 노출을 시키면서, GA(구글애널리틱스)로 트래픽을 분석하여 더 개선시키는 방향으로 진행했다.
GPT3 사용법, 설치부터 쉽게! 슬로건, 동화 만들기까지? KoGPT3 등장?
6-1 파이널 프로젝트 : 자연어처리, kogpt2를 이용한 슬로건 생성 목차 1. SKT-AI/KoGPT2와 자연처(NLP) 2. 데이터 전처리 (나무위키, 블로그) 3. KoGPT2와 기능구현 (인풋 아웃풋 조정) 4. 짧은 텍스트 / 문장
0goodmorning.tistory.com
읽으면 유용한 글 : GPT3

기간 : 2021.07.12 ~ 2021.08.18 (1 달 조금 넘게)
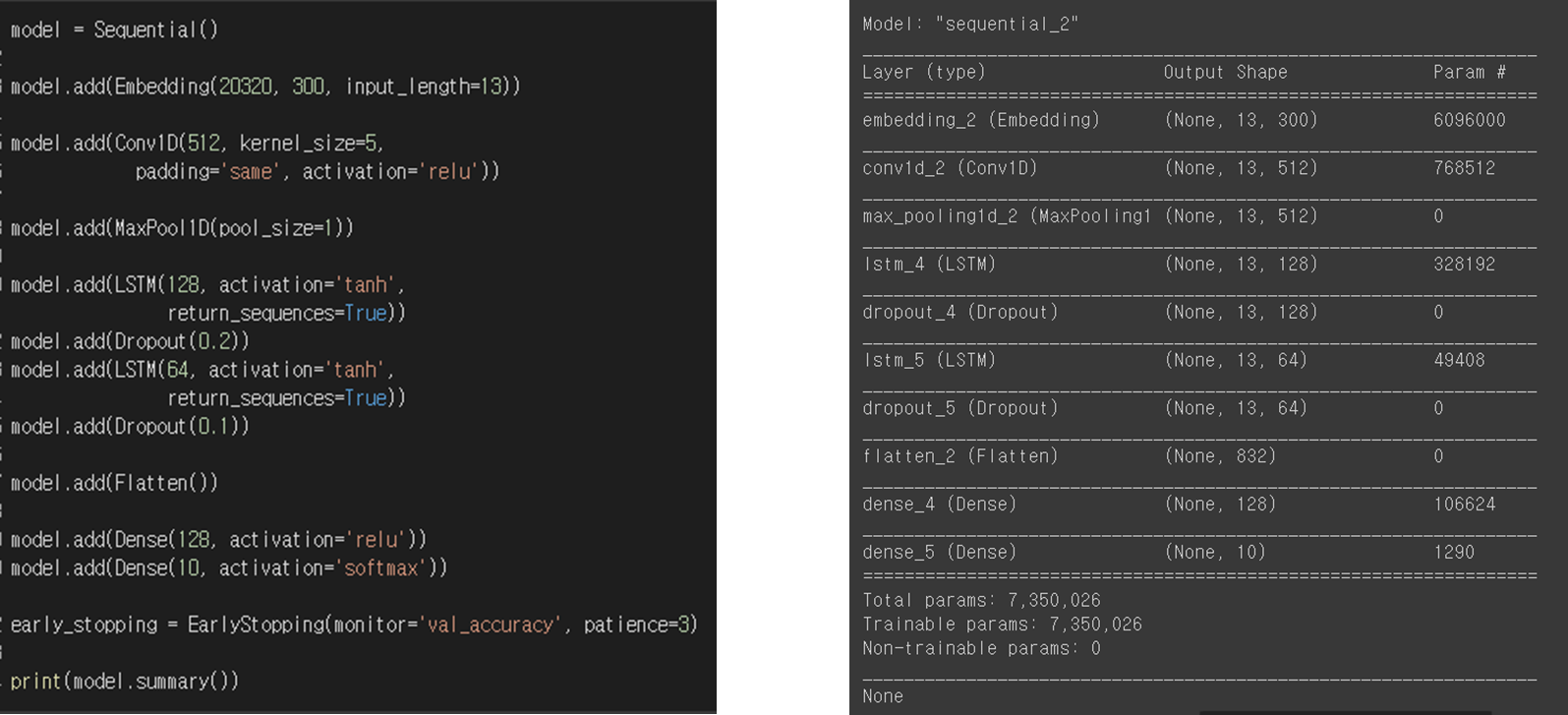
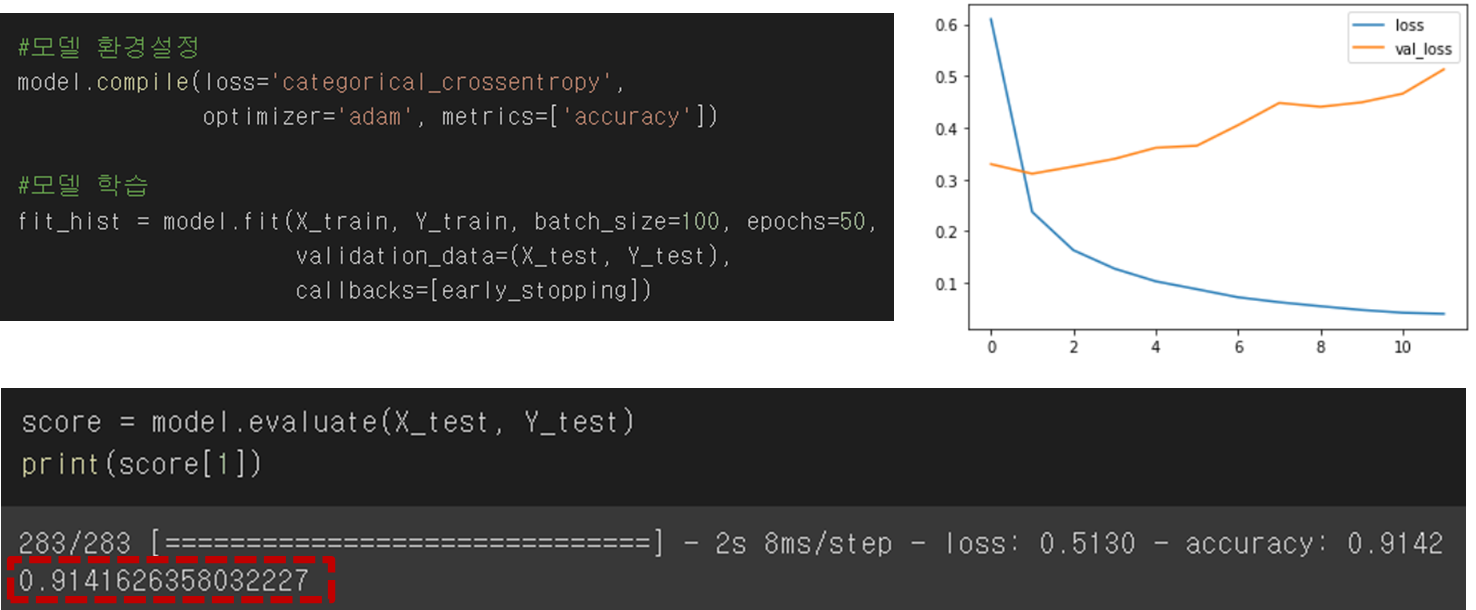
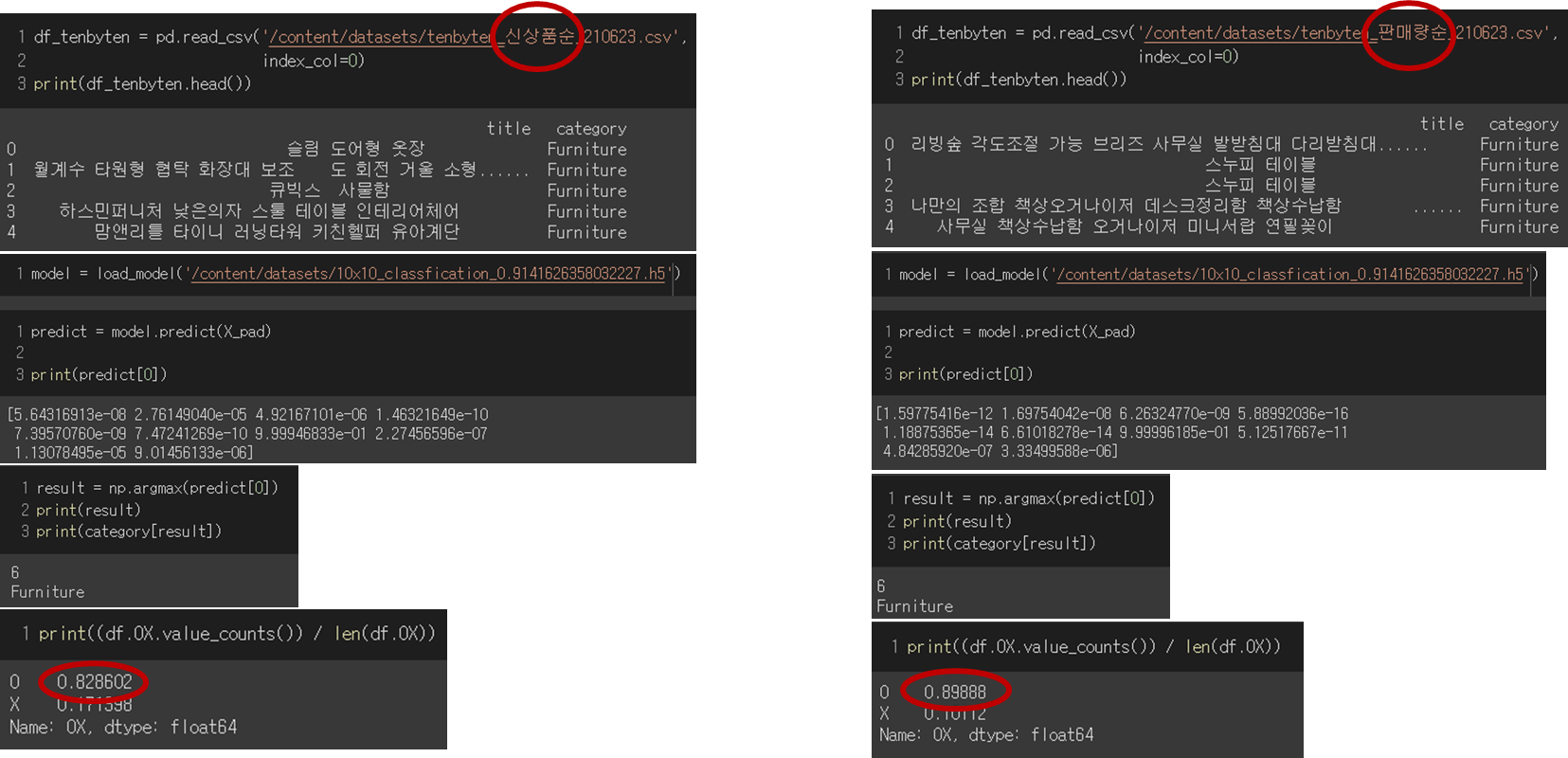
사용 기술은 그림을 참고.
파이널 프로젝트라서 거창한 것을 해보려고 다양한 아이디어를 냈으나 쉽게 주제를 결정할 수 없었다. 이것저것해보다가 시간은 4주도 남지 않아서 처음에 진행하려고 했던 슬로건 생성을 해보자고 했다. 과연 슬로건처럼 간단하면서 임팩트 있는 문구를 인공지능이 생성할 수 있을까? 하는 의문이 있었지만 인공지능은 해냈다. (우리가 해냈다)
이번 시간을 통해서 자연어처리에 대해서 많이 공부를 할 수 있었고, gpt2와 프로젝트가 끝난 이후 gpt3에 대해서도 추가적으로 공부를 하였다. 주로 인공지능을 통해서 분류를 하거나 예측을 하였는데, 새로운 문장을 생성한다는게 참 신기했다.


GPT(Generative Pre-trained Transformer)는 언어모델로 '자연어 디코더 모델'이라고 생각하면 쉽다. 자연어 처리 기반이 되는 조건부 확률 예측 도구이며, 단어가 주어졌을 때 다음에 등장한 단어의 확률을 예측하는 방식으로 학습이 진행 된다. 문장 시작부터 순차적으로 계산한다는 점에서 일방향을 보인다.

KoGPT2 skt-ai에서 만든 한글 디코더 모델. KoGPT2에서는 기존 GPT의 부족한 한국어 성능을 극복하기 위해 많은 데이터(40g)로 학습된 언어 모델로서 한글 문장 생성기에서 좋은 효과를 보인다고 한다. 시 생성, 가사 생성, 챗봇 등의 서비스 구현한 사례가 있다.
단순히 모델 사용보다 자연어를 어떻게 처리할지 많은 공부를 하게 됐다. 간단하게 정리한 부분을 추가적으로 공유하려고 한다.
자연어 처리로 할 수 있는 것들
-텍스트 분류 (스팸 메일)
-감성 분석 (긍/부)
-내용 요약 (추출/ 생성)
-기계 번역 (번역)
-챗봇

자연어 처리 과정
-Preprocessing (전처리) : stopwords 불용어 제거, 형태소 분석, 표제어 추출 / 컴퓨터가 자연어를 처리할 수 있게
-Vectorization (벡터화) : 원핫인코딩, count vectorization, tfdif, padding
-Embedding : word2vec, doc2vec, glove, fasttext
-Modeling : gru, lstm. attention
*Transfer learning (전이 학습) : pretrain한 임베딩을 다른 문제를 푸는데 재사용
*Fine-tuning (파인 튜닝) : pretrain된 모델을 업데이트하는 개념. / 엔드투엔드에서 발전
임베딩
- 자연어를 숫자의 나열인 벡터로 바꾼 결과 혹은 과정 전체 (벡터 공간에 끼워넣는다)
- 말뭉치의 의미, 문법 정보가 응축되어 있음, 단어/문서 관련도 계산 가능
- 품질이 좋으면 성능이 높고 converge(수렴)도 빠르다
- NPLM(최초) / Word2Vec(단어수준) / ELMo(문장수준), BERT, GPT
단어 문장간 관련도 예상 / t-SNE 차원 축소 100차원->2차원으로 / Word2Vec 개선 모델 FastText / 행렬 분해 모델 / 에측 기반 방법 / 토픽 기간 방법 등으로 나뉨
잠재의미분석 : 말뭉치의 통계량을 직접적으로 활용
희소 행렬 - 행렬 대부분의 요소 값 0
단어-문서행렬, TF-IDF, 단어-문맥 행렬, 점별 상호정보량 행렬
단어수준 임베딩 단점 : 동음이의어 분간 어려움
=> ELMo, BERT, GPT 시퀀스 전체의 문맥적 의미 함축해서 전이학습 효과가 좋음
*다운스트림 태스크 : 풀고 싶은 자연어 처리의 구체적 문제들
(품사 판별, 개체명 인식, 의미역 분석, 형태소 분석, 문장 성분 분석, 의존 관계 분석, 의미역 분석, 상호참조 해결)
*업스트팀 태스크 : 다운스트렘 태스크 이전에 해결해야할 괴제. 단어/문장 임베딩을 프리트레인하는 작업
토큰 : 단어, 형태소, 서브워드
토크나이즈 : 문장을 토큰 시퀀스로 분석
형태소 분석 : 문장을 형태소 시퀀스로 나누는 과정

TF-IDF : 백오브워즈 가정(어떤 단어가 많이 쓰였는가) / term frequency inverse document
순서 정보는 무시하는 특징이 있다. 주제가 비슷하면 단어 빈도 또는 단어 비슷할 것이다. (정보 검색 분야에서 많이 쓰인다.)
사용자 질의에 가장 적절한 문서 보여줄 때 코사인 유사도를 구해서 보여준다.
-TF : 특정 문서에 얼마나 많이 쓰이는지
-DF : 특정 단어가 나타난 문서의 수
-IDF : 전체 문서를 해당 단어의 DF로 나눈 뒤 로그를 취함. 값이 클수록 특이 단어
(단어의 주제 예측 능력과 직결 됨)

ELMo, GPT : 단어가 어떤 순서로 쓰였는가? 주어진 단어 시퀀스 다음에 단어가 나올 확률이 어떤게 큰지?
n-gram (말뭉치 내 단어들을 n개씩 묶어서 빈도를 학습), 다음 단어 나타날 확률 조건부확률의 정의를 활용해 최대우도추정법으로 유도 => 한 번도 나오지 않으면 확률이 0이 되므로 보완을 해줘야 한다
마코프 가정 (한 상태의 확률은 그 직전 상태에만 의존한다) => 그래도 등장하지 않았던 단어 나오면 0이 되기 때문에 백오프, 스무딩 방식 (높은 빈도를 가진 문자열 등장확률을 일부 깎고, 등장하지 않은 케이스에 확률 부여
뉴럴 네트워키 기반 언어 모델 : 다음 단어를 맞추는 과정 학습 (엘모,지피티)
마스크 언어 모델 : 문장 전체를 보고 중간에 있는 맞추기 (BERT)

Word2Vec : 어떤 단어가 같이 쓰였는가 (분포 가정) 단어의 의미는 곧 그 언어에서의 활용이다?
타깃단어와 그 주위에 등장하는 문맥단어 계산 / 분포 정보가 곧 의미? 의문점
형태소 분류 - 계열 관계 : 해당 형태소 자리에 다른 형태소가 대치 될 수 있는지
품사 분류 – 기능(주어, 서술어), 의미(같은 뜻), 형식(이름, 성질, 상태)
형태는 같지만 기능과 의미가 달라질 수 있다.(기능과 분포는 다르지만 밀접한 관련)
PMI 두 단어의 등장이 독립일 때 대비해 얼마나 자주 같이 등장하는지 (단어 가중치) 단어-문맥 행렬
'도전하자. 프로젝트' 카테고리의 다른 글
| 6-3 파이널프로젝트 KoGPT2와 짧은 텍스트/문장 유사도 (1) (0) | 2021.09.03 |
|---|---|
| 6-2 파이널프로젝트 나무위키, 네이버 블로그 크롤링 및 전처리 (4) | 2021.09.02 |
| 5-3 파이썬 팀프로젝트 PyQt5로 간단 GUI 프로그램 만들기 (자동완성 기능) (2) | 2021.08.14 |
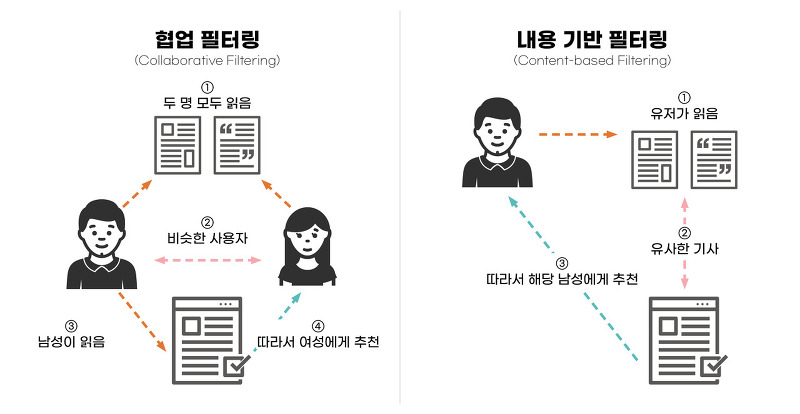
| 5-2 파이썬 팀프로젝트 추천시스템 (자연어 NLP / TF-IDF, Word2Vec) (0) | 2021.08.13 |
| 5-1 파이썬 팀프로젝트 - 추천 시스템과 편향 방지 (유튜브의 알고리즘?) (0) | 2021.08.12 |