336x280(권장), 300x250(권장), 250x250, 200x200 크기의 광고 코드만 넣을 수 있습니다.
기흥역, 화재 발생... 일시적 운행 중단 및 승객 대피
18일 오전 7시 40분경, 용인 경전철 기흥역에서 화재가 발생해 긴급 대응이 이루어졌다. 초기 보고에 따르면, 화재는 역 내부의 에스컬레이터 하단 기계실에서 시작된 것으로 추정된다. 화재 발생 직후 승객들이 빠르게 대피했으며, 다행히 현재까지 인명 피해는 보고되지 않았다.
현장에 출동한 소방당국은 약 30분 만에 화재를 진압했으나, 연기와 열로 인해 역 시설 일부가 손상되었다. 이로 인해 경전철 운행이 일시 중단되었으며, 기흥역을 경유하는 열차는 인근 정류장에서 회차 운행 중이다.
용인시 관계자는 “화재 원인 조사와 더불어 시설 점검을 신속히 진행해 조속히 운행을 재개하겠다”고 밝혔다. 또한 승객들의 안전을 최우선으로 고려해 복구 작업을 철저히 진행할 계획이라고 덧붙였다.
기흥역을 이용하는 시민들은 임시 운행 계획을 확인하고, 대체 교통수단을 이용할 것을 권고받고 있다.
336x280(권장), 300x250(권장), 250x250, 200x200 크기의 광고 코드만 넣을 수 있습니다.
메종프랑시스커정 가품 vs 정품 간단비교 / 중고나라, 번개장터 모르면 사기당함
번아웃이 와서 그런지 원래 하던 것도 다 안 하게 되고, 저번에 메종프랑시스커정(MFK) 향수 글도 올리려다가 못 올렸다. 나름 그래도 열심히 썼는데 임시저장된 글에 사라졌다. 그냥 다시 쓴다는 마음으로 쓰려고 하는데 많은 도움이 됐으면 좋겠다. 도입부는 사족이 많으니 정가품 비교하고 싶으신 분은 스크롤을 조금 내려주시고, 커정 향수 관심이 많으시면 읽어주셔도 좋아요.
사족
바카라 루쥬 vs 사틴무드 vs 비슷한 향들
개인적으로 커정 제품에서 바카라 루쥬 540을 너무 좋아한다. 달달하면서 요굴하지만 너무 강하지 않은 향. 사바사지만 쇠향, 치과향 때문에 적절한 밸런스를 유지해주는거 같다. 어떤 사람에게는 치과향이 강하게 나서 불호라고 하지만 전 괜찮아서. 비슷한 요굴향이 나는 제품으로 사틴무드, 르라보 어나더13이 있고, 재즈클럽도 비슷하게 달달하다고 한다.
백화점에 가서 바카라 루쥬와 사틴무드 여러 번 고민을 했다. 향이 둘다 너무 좋아서.. 각 왼뿌 오뿌를 해봤는데 처음에는 바카라 루쥬를 들였지만 사틴무드도 역시 들이게 됐다. 사틴무드의 경우 정말 미친 존재감을 내뿜는다. 시향지를 받아왔는데 1달이 지나도 향이 그대로 머물러 있다. 그리고 뭔가 고급지면서 스며드는 달달함이 매력적이다. 그에 비해 루쥬는 조금 더 부드럽다고 해야 되나? 둘다 지속력이 대단한데 오전에 뿌리고 가면 밤까지 어느정도 느껴진다. 옷에는 며칠이 지나도 남아 있는다.
르라보 어나더13. 간택을 받아야 하는 향수. 죽음의 피맛을 느끼는 향수. 시향을 했는데 약간 소름끼치는 장면을 목격한 것 같은 느낌이다. 잔인하면서 피가 튀기는 장면, 살인자가 상대방을 죽이고 그 피맛을 즐기면서 웃고 있는거 같은 느낌. 매혹적이면서 영안실 냄새와 쇠향의 조화 그리고 살짝 달달한. 너무 강하게 와서 바카라 루쥬도 심하면 치과향이 강하게날 수 있겠구나라고 생각이 들었다. 재즈클럽은 아직 시향을 못해봐서
이전 글은 킬리안 정품 가품 비교 글이다. 중고나라에서 특히 가품을 많이 팔고 있다. 다시 한 번 조언을 드리자면, 가격이 싸면 의심할 것. 향린이면 택이 없으면 깔끔하게 포기할 것.
왼쪽 가품, 오른쪽 정품
1. 박스 폰트, 색상 확인
커정 향수는 고급지다. 색이며 폰트며 싸구려 티가 나지 않는다. 실크무드의 경우 색상부터 시작해서, 폰트 두께, 금박 다 차이가 났다. 바카라 루쥬의 경우 540은 그냥 프린팅한 느낌. 자세히 보면 왼쪽과 가운데 사진은 붉은 색이 흐릿하다는 것을 알 수 있다. 하지만 이전 글에도 언급했듯이 가품들 퀄리티가 점점 올라가기 때문에 단순히 폰트 색상 가지고는 판단하기 쉽지 않다.
특히나 카메라의 화질, 각도, 방향, 조명에 따라서 구분이 잘 안 되고, 본인이 박스를 가지고 있지 않으면 구분이 더 어렵다. 이 부분은 참고용 정도로만 생각하고 다음으로 넘어가자.
왼쪽 정품, 오른쪽 가품
2. 향수 폰트, 색상 확인
향수 역시 폰트와 색상으로 가품과 진품이 구별이 가능한 것도 있다. 정품의 경우 날렵하고 정교하지만, 가품의 경우 폰트가 두껍고 싸구려 티가 난다. 중고나라에 올라왔던 경우는 더 두껍고 영롱한 병 색이 이상한 느낌이다. 하지만 이 역시 육안상으로는 오차가 있을 수도 있고, 정품과 가품이 동시에 있을 때나 구분이 가능하지 역시 쉬운 방법이 아니다.
왼쪽 정품, 오른쪽 가품
3. 뿌~ 하는 분사구 모양을 찾기
커정 조향사가 가품이 향수가 나온 것을 보고 살짝 삐쳤는지 입이 튀어나와서 분사구가 뿌 모양을 하고 있나 봅니다. 가품의 경우는 직선으로 되어 있어서 구분이 조금 쉽다. 그리고 추가로 확인해야할 부분이 있으니 우선 3번부터 이해하시고 넘어가면 가품에 당할 일은 없을 것이다.
왼쪽 정품, 가운데 정품, 오른쪽 가품
여러 사진을 가져와봤는데 바로 보이시나요? 뭔가 더 동그랗게 올라와 있다. 가품의 경우 길쭉하다다. 헷갈리실까봐 다양한 각도에서 찍은 사진들을 준비했으니 참고.
왼쪽 정품, 가운데 정품, 오른쪽 가품
이제는 정확히 보이시나요? 이렇게 위쪽이 튀어나와 있는 애들이 정품이고 길쭉한 애들이 가품. 하지만 한 가지 더 참고해야할 부분이 있다.
4. 플라스틱이 좋아
3번 사진을 보시면 화살표로 표시한 부분이 있다. 뿌한 입모양 말고도 정품의 경우는 모든게 플라스틱으로 되어있다. 가품은 알루미늄?으로 되어있다. 이 부분을 왜 언급하냐면 기출 변형들이 종종 등장하기 때문.
이건 가품일까요? 뿌하는게 없으니 가품이네!라고 생각할 수 있겠지만 정품이다. 그것도 파정(파워정품). 엥???이라고 하실 수 있겠지만 왼쪽 사진 잘 보시면 국문택이 있다. 너무나도 명확하게 있다. 그래서 3번과 4번을 같이 봐야 한다. 오른쪽 사진을 보면 모든게 다 플라스틱으로 이어져 있다.
이것 또한 마찬가지. 뿌한 모양이 없지만, 저기 맨 윗쪽에 보이는 하얀 국문택. 파정이다. 하지만 이 향수 또한 노즐 주위가 모두 플라스틱이다. 특히 가품 중에 미개봉이라고 해서 싸게 파는 경우가 있어서 확인이 불가능한 경우가 많다. 포장 뜯어서 보여달라고 할거 아니면 그냥 지나가는게 오히려 마음이 편하다.
백화점에서 마음 편하게 국문택이 있는 향수를 사든, 아니면 시빌리지, 바이슈코 같이 보장된 곳에서 사는게 찝찝함을 덜 수 있다. 다음에는 톰포드 가품 구분법에 대해 알아보려고 한다.
336x280(권장), 300x250(권장), 250x250, 200x200 크기의 광고 코드만 넣을 수 있습니다.
킬리안 정품 vs 가품 비교 / 중고나라, 당근거래시 100% 사기 예방
요즘 향수에 빠지면서 시향을 많이 하고 있다. 확실히 비싼 향수들은 그만큼의 값어치를 한다는 것을 느꼈다. 코로나 때문에 시향을 하고싶어도 못 했는데 최근에 풀리면서 많이 돌아다녔다. 어떤 조향사 하시던 분이 프레데릭 말 엉빠썽이 자신의 인생 향수라고 해서 그거부터 맡아봤는데 자연 그대로를 담았지만 내 타입은 아니었다. (나중에는 후기들 크롤링해서 추천시스템을 만들어야지..)
백화점을 돌아다니면서 웬만한 브랜드들의 대표 향수들을 맡아봤는데.. 그중에 킬리안, 메종프랑시스 커정, 톰포드가 마음에 들었다. 백화점에서 구매하면 정품 가품 마음은 편하겠지만 잔고는 텅장이 될거 같아서 중고거래를 좀 알아봤다. 근데 가품들이 왜 이렇게 많은지 ㅠㅠ 정보도 별로 없어서 마음 고생하실분들을 위해서 사기 예방 방법들을 모아봤다.
0. 가격이 싸면 일단 의심하라
너무나 당연한 얘기지만, 본품을 30만원에 사놓고 누가 거의 새제품을 15만원 이하에 팔까? (그런 천사분들은 저한테 연락주세요^^) 진짜 급전이 필요한 사람이라면 관련 판매글을 봐야 한다. 향수에 관심이 있는 사람인가? 다른 향수들은 정품을 팔고 있는가?
근데 대부분의 의심이 가는 사람들은 다양한 브랜드의 새제품을 싸게 판다. 그것도 특정 공통적인 향수만 예를 들어 톰포드 로스트 체리나 킬리안 블랙팬텀, 굿걸곤베드, 블레이-부 쿠셔 아베끄(나랑잘래). 대부분 정품급, 병행수입 등을 붙인다.
가격이 너무 저렴하다고 싶으면 아쉽지만 패스하는게 나을 수도 있다.
1. 국문텍, 백화점 영수증 확인하기
국문텍까지 조작하는 사람은 아직까지 못 봤다. 백화점 영수증이라도 있으면 일단 안심하고 마음을 놓을 수 있다. 면세점일 경우 국문텍이 없는 것으로 아는데 영수증 또는 다른 확인하는 방법을 밑에 자세히 써놓겠다.
하지만 킬리안의 경우는 뚜껑을 돌려서 열 수 있어서 주의해야한다. 리필이 되는 향수의 경우 마음만 먹으면 다른 향수로 바꿔치기할 수도 있기 때문에, 미리 시향을 해보고 차이가 나는지 만나서 확인해야 한다. 가격이 한 두푼이 아닌데 웬만하면 직거래로 하기.
당근마켓이나 중고나라, 번개장터에서 공병을 구입하는 사람들이 있다. 킬리안, 톰포드의 경우 공병 자체가 매력이 넘쳐서 모을 수도 있지만 불손한 의도를 가진 사람들이 있다.
2. 숨은 그림 찾기
*5개 킬리안 쇼핑백(종이백) 중에 다른 것을 찾으세요.
마치 백화점에서 산것처럼 하기 위해서 쇼핑백까지 만들어서 파는 경우가 있다. 어떤게 가품인지는 여러 분들이 알아서 판단할 수 있을 것 같아서 언급은 안 하겠습니다. 쇼핑백 이외 박스나 킬리안 소개서는 폰트도 비슷해서 구별하기 쉽지 않다.
왼 : 정품 / 오 : 가품
3. 다른 그림 찾기
100% 정확하지는 않지만 이 부분도 정품과 가품(짝퉁) 사이에 차이가 있습니다. 자세히 비교 하시면 킬리안(Kilian)의 K의 두께가 뚜껑에서 다르다는 것을 알 수 있습니다. 아무리 정교하게 만들어도 이거까지 따라하기는 쉽지 않은 모양이네요.
왼 : 정품 / 오 : 가품
미세한 차이가 살짝 보이긴 하지만 육안으로 구분하기 쉽지 않습니다. 본인이 원래 킬리안 향수가 있다면 사진과 비교를 할 수 있지만 이걸로 100% 거를 수는 없습니다.
왼 2 : 정품 / 오 2 : 가품
4. 무작정 확대하기
또 문제의 K네요. 정면을 확인하면 킬리안의 K의 모양이 다르다는 것을 확인할 수 있습니다. 굿걸 곤 베드(Good girl gone Bad)의 경우는 특히 차이가 많이 났습니다. 하지만 이것도 구분하기 쉽지는 않고, 몇몇 가품에서는 K 옆에 부분이 미세하게 떨어져 있는 것을 확인할 수 있어서... 붙어 있으면 의심만 하고 넘어가세요.
왼 : 정품 / 오 : 가품
블랙 팬텀의 경우 K 옆에 부분이 떨어져 있는 경우도 있기 때문에, 떨어져 있으면 정품이다(X), 붙어있으면 가품일 확률이 있다(O)로 생각하시면 될거 같습니다. 그리고 코팅(?)이 얼마나 아래까지 있는지도 정품 가품에 따라 다른데 이것도 사진의 각도에 따라 달라져서 넘어가겠습니다.
5. 측면을 확인하기
본인이 잘생겼는지, 이쁜지 확인하려면 그림자를 확인하라고 했다. 이목구비가 뚜렷하고 조각 같은 연예인들이나 아이돌들은 그림자까지 예쁘다. 김태희는 마네킹이 따로 없어 보인다. 하지만 킬리안은 다르다. 뭔가 흐리멍덩해야 정품이다.
왼 : 정품 / 오 : 가품
왼쪽 사진은 블랙팬텀. 오른쪽 사진은 여러 킬리안을 모아놓은 사진. 뭔가 가짜 같이 보이는게 정품이다. 오히려 뚜렷하게 문양이 되어 있는 제품이 가품이다. 뭔가 너무 정교하게 잘 만들어진 것 같으면 가품이라고 생각하면 된다.
왼 : 정품 / 오 : 가품
6. 정품 가품 구별 끝장내기
솔직히 이거 때문에 글을 썼다. 왠지 모르겠지만 킬리안 가품들은 캡을 빼면 100% 모양이 다르다. 캡에 K가 있나 없나에 따라서 정품/가품을 구별한다고 한다는데 정품에도 K가 없는 경우가 있다.
위 사진은 킬리안의 엔젤스 셰어(시향하고 푹 빠졌다)인데 길쭉한 애가 정품이다. 가품은 뭔가 허접한 스프링이 잘 보인다. 톰포드도 이와 비슷한 구조라서 다 비슷한가 싶었는데, 조말론의 경우 뭔가 더 뭉툭한게 정품이라 모든 향수에 적용하기는 어렵다.
혹시나 정품/가품을 알 수 있는 방법이 있으면 댓글로 공유해주세요. 살짝 두려운 점은 이런 글들을 보고 가품을 정품처럼 따라 만드는게 아닌가 걱정이 되기도 한다.
오랜만에 글을 썼는데.. 사무자동화 마지막 글이네요. 우선 생각했던건 여기까지고 추가로 필요한 부분 있으면 제가 또 만들지 않을까.. bs4나 셀레니움(selenium)으로 크롤링까지는 금방 완성이 되는데, 자동 캡쳐나 스크린샷을 찍는 방법은 처음으로 시도했다. 검색을 해보면 전체화면 캡쳐를 하는게 대부분이고, 내가 원하는 element나 특정 부분 캡쳐는 설명이 별로 없었다.
복잡하게 좌표값이나 height, witdh를 다 구해서 전체화면 스크린샷을 찍고 원하는 부분만 가져오는 것도 많았다. 물론 크롬에서 쉽게 특정 element를 캡쳐하는 방법도 있었다. 약간 신세계를 경험하는 것 같았는데 자동화가 아니다 보니 패스.. 그래도 짧게 소개해보자면
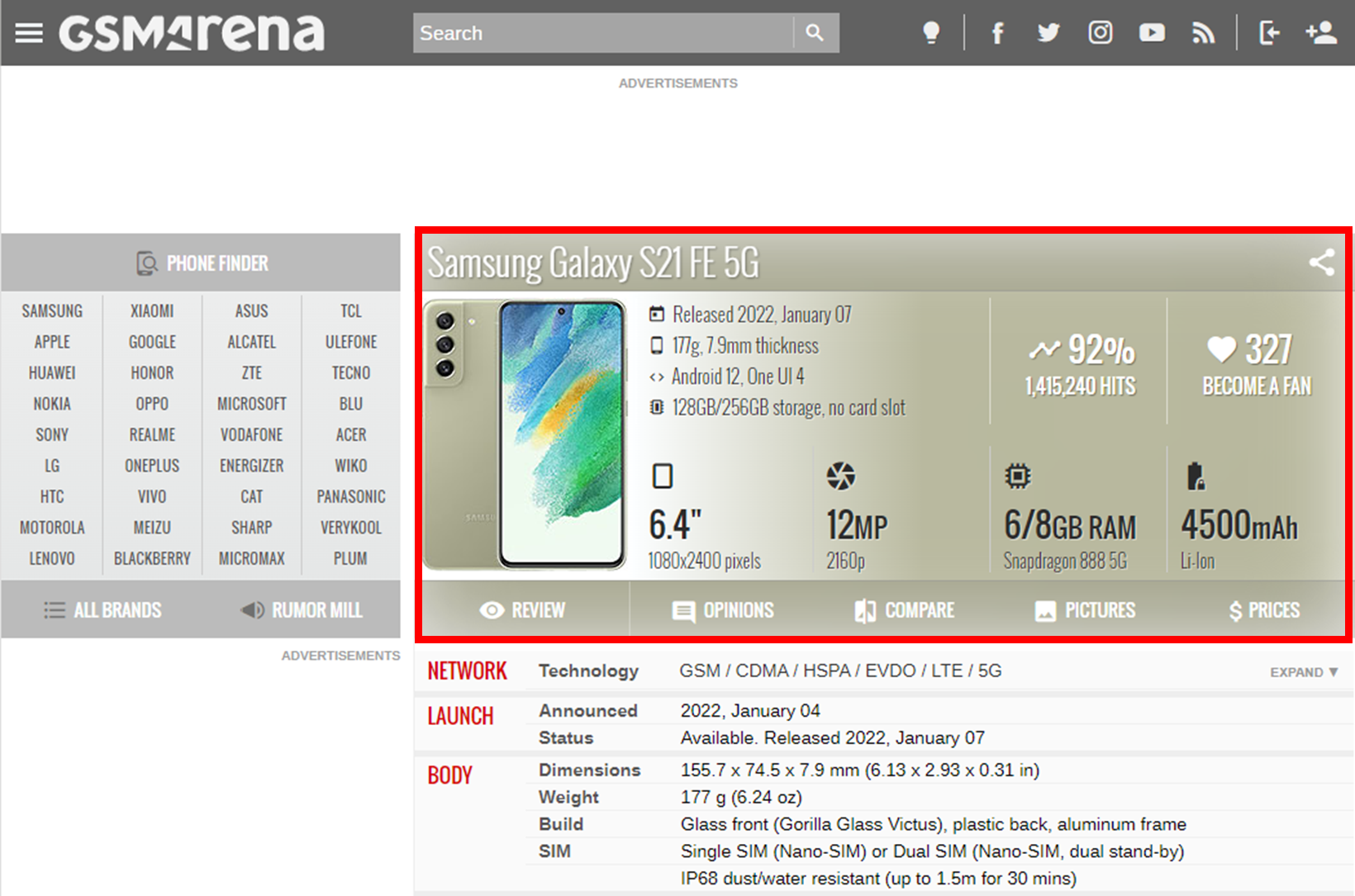
GSMARENA라는 싸이트에서 빨간색 박스를 친 부분의 사진만 가져오고 싶을 때, 우선 F12 개발자 도구를 켠다. 그 다음에 Elements에서 저 부분을 포함하는 class나 id를 찾고 클릭을 한다. 이후에 shift + crtl + p 를 누른다.
그러면 개발자용 명령창이 뜨게 되는데 약자로 cnod를 검색. capture node screenshot이 나오게 되는데, 클릭하면 바로 캡쳐가 된다. 심지어 결과도 깔끔하고 화질도 나쁘지 않다. 그러면 뭐하나.. 자동이 아니면 매번 이 작업을 반복해야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
듀얼 모니터 화면에서 캡쳐가 됐다!! 하지만 화면이 잘리지 않으려면 화면을 축소해서 찍어야 했다. 사람들마다 셀레니움 화면을 축소하는 다양한 방법을 소개시켜줬는데 잘 안 됐다. 기본 설정에 들어가서 바꾸라는 사람부터 zoom out을 하라는 것도 있었지만, 값을 바꾸게 되면 css에도 영향을 미치는 것 같았다.
1
2
3
4
5
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
document.body.style.zoom을 활용하게 되면 안 된다. document.body.style.transform을 사용해야 한다. 원하는 요소가 한 페이지에 나오면 좋겠지만, 아닌 경우도 있으니 쓰시면 될 것 같습니다. 문제는 어느정도 해결한 듯 보였으나 원하는 이미지가 서로 다른 element에 있어서 이미지 병합까지 하게 됐다.
밑에 과정은 gsmarena에서 기본적인 정보를 크롤링하고 이미지 캡쳐, 병합하는 과정입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
from bs4 import BeautifulSoup
import pandas as pd
import requests
import re
#환율
def exchange_rate(today_rate, price,r) : #r은 반올림 자리 숫자
이미지 병합, 리사이징까지의 과정이 있습니다. 화면을 축소하니까 사진을 잘못 찍는 경우가 있어서, 사진 1장은 원래 크기에서 찍고, 다른 1장은 축소해서 찍었네요. 그리고 리사이징을 해서 병합하는 복잡한 과정을 거쳤습니다. 여러분들이 도전하는 크롤링과 자동 캡쳐 스크린샷 코드는 문제가 없길 바랍니다 ㅠㅠ
지난번 글에서는 실무에서 무조건 쓰는 VLOOKUP, INDEX/MATCH 함수를 파이썬으로 구현하는 방법에 대해서 소개해드렸습니다. 몇 천개가 넘는 데이터를 INDEX/MATCH를 사용하여 여러 조건을 따졌을 때, 밑에 프로세스 계산중이라고 뜨면서 엑셀이 멈추거나 버벅거렸는데 파이썬으로는 30초 안에 해결된 거 같네요.
엑셀 함수 자동화 기능들
- 띄어쓰기 다른 문자열 비교 (조건 찾기 개선)
- 포함 여부 찾기
- 필터링 방법 (있을 때, 없을 때)
- 인덱스 찾기
- 모든 제품 소문자/ 대문자 바꾸기
- 찾는 조건 값 한 번에 바꾸기
- 여러 시트 합치기
띄어쓰기가 다른 문자열
VLOOKUP 기능을 사용하면서 느꼈던 점은 제품의 경우 대소문자가 달라도 같은 제품으로 인식하는데, 띄어쓰기나 문자가 조금만 다르면 조건에 걸리지 않은 치명적인 단점이 있었습니다.
예를 들어 'GALAXY Z FLIP3' = 'galaxy z flip3' 는 조건에서 인식을 하는데 'GALAXY ZFLIP3'나 'GALAXYZFLIP3'는 조건에 해당하지 않아서 #N/A 값이 나오는 황당한 케이스가 너무 많았습니다. 이는 파이썬에서 금방 해결이 가능합니다.
1
2
3
4
5
6
7
8
9
10
11
import pandas as pd
target ='GALAXY Z FLIP3'
data = ['galaxy z flip3','GALAXY ZFLIP3', 'GALAXYZFLIP3']
단어를 .lower().replace(' ', '')을 사용하시면 간단하게 해결이 됩니다. 여기서 중요한 것은 변수 자체를 바꾸는 것이 아닌, 비교할 때만 소문자로 만들고 공백(띄어쓰기)를 임시로 제거해야 합니다. 본래 값을 바꾸게 되면, 나중에 입력하는 값에 수정된 값이 입력될 수 있습니다. 예를 들어 'galaxy z flip3'가 아닌 'galaxyzflip3'이 입력이 됩니다.
포함 여부 (문자열, 숫자) / 숫자만 뽑기
1
2
3
4
5
6
7
import pandas as pd
data = ['galaxy z flip3','GALAXY ZFLIP3', 'GALAXYZFLIP3']
contain_num 함수는 문자열을 하나하나 분리해서 그 안에 숫자가 있는지 확인을 합니다. isdigit()이 숫자면 True, 아니면 False를 반환 하게 됩니다. 그래서 숫자가 포함이 되면 return 값이 True가 되기 때문에, if contain_num(i)를 실행하게 됩니다. 여기서 궁금한 것이 그렇다면 숫자만 찾고고 싶을 수도 있어서 추가로 팁을 드리겠습니다.
1
2
3
4
5
6
7
8
9
10
11
import re
def contain_num(s):
return any(i.isdigit() for i in s)
data = ['galaxy z flip','GALAXY ZFLIP2', 'GALAXYZFLIP3']
for 문을 돌릴 필요 없이 원하는 컬럼에 str.lower()를 사용하면 모든 제품이 소문자로 변경된다. 반대는 str.upper() 사용!
특정 데이터 한 번에 변경
갤럭시 Z플립3 5G만 5만원씩 할인을 한다고 했을 때, 'df.loc[조건, 열] = 원하는 값' 을 입력해주시면 됩니다.
여러 데이터 합치기
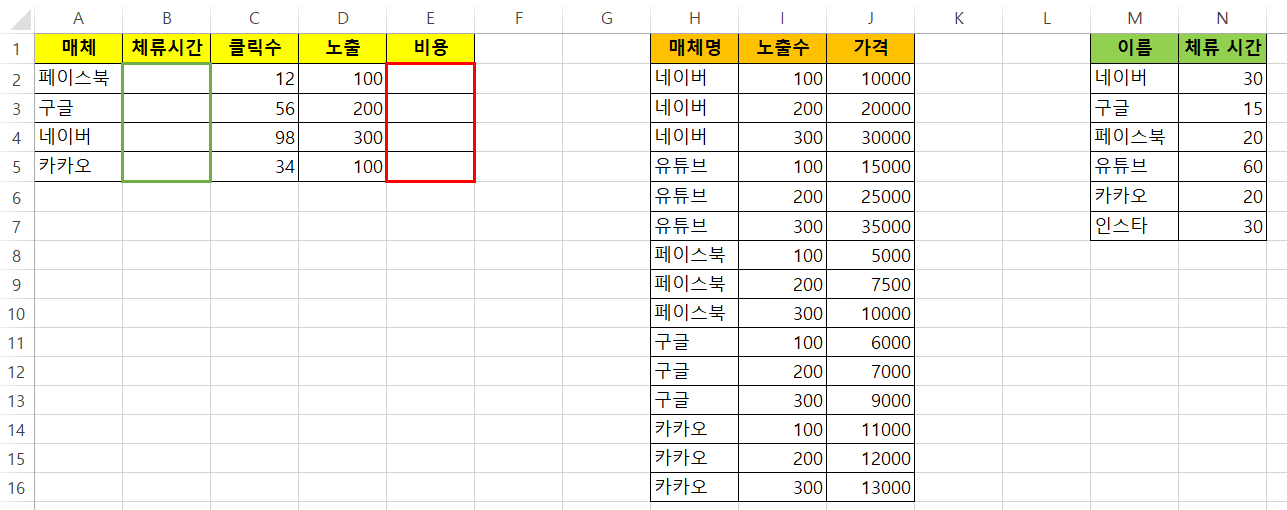
위와 같이 phone과 phone_price라는 시트가 있습니다. phone 시트에서 Product와 Price 열만 가지고 오려면 어떻게 할까요?
pd.concat([기존 시트, 추가 시트1, 추가 시트2], join = 'inner) concat과 inner join을 사용하시면 기존 컬럼을 유지하게 됩니다.
append 사용하기. 앞으로 관리를 할 때 Company와 Review 열을 추가로 가져오고 싶으면, 열에 맞게 값이 추가가 됩니다. 기존 시트에 열이 없으면 새로 가져오는 시트에서 열을 가져오게 됩니다. 그래서 기존 시트는 Company와 Review 열에 NaN 값이 들어가게 됩니다.
저번처럼 모듈을 불러오고 반복문을 사용합니다. 지난번에는 facebook, exposure라고 변수명을 지정했는데, 이번에는 간편하게 col_A, col_D 라고 지정하겠습니다. 지난 내용을 단지 for 문 안에 집어넣은 것이기 때문에 어려움은 없지만, 파이썬을 아예 처음 접하신 분들을 위해서 잠깐 설명을 하자면
값이 4개 밖에 되지 않아서 직접 쳐도 된다고 생각하지만, 저희가 다루는 데이터 양이 많습니다. 그래서 이를 반복문으로 돌리는 것입니다. for문의 기본 구조를 보자면,
for [변수] in [문자열, 리스트, 튜플] :
[수행부분]
이런 식으로 구성이 되어 있는데, [문자열, 리스트, 튜플] 등을 순서대로 돌면서 [변수]에 넣어주게 됩니다. range(4)를 할 경우에 [변수]에 0,1,2,3 까지를 넣어주게 됩니다. range의 경우 0부터 시작해서 range 안에 숫자-1 까지의 숫자를 사용합니다.
col_A = df['매체'][i] 는 for문을 돌면서 변수가 0 일 때 페이스북, 1 일 때 구글, 2 일 때 네이버... 이런 식으로 변경이 되는 것입니다. 몇 번 사용하시다 보면 자연스레 익히게 됩니다. 어떤 식으로 돌아가는지만 생각하시면 될 것 같네요.
만약 페이스북의 노출이 400이 되면 어떻게 될까요? 엑셀에서도 #N/A 값이라고 하면서 오류가 뜹니다. 파이썬에서도 위와 같은 코드로 진행할 경우 마찬가지로 오류가 뜨게 됩니다.
이렇게 오류가 뜨게 되는 이유는 매체명이 페이스북이면서, 노출수가 400인 케이스가 존재하지 않기 때문입니다. 그런데 .values[0]으로 값을 가져오라고 해서 index 0 is out of bounds가 뜨게 되는 것입니다. 이 오류를 해결하기 위해서는 간단하게 한 줄만 추가하면 됩니다.
len() 함수는 문자열의 길이를 구하는 함수인데, 아무것도 존재하지 않을 때 0 이 된다. 그리고 파이썬에서 0은 False로 인식하기 때문에, len(col_E)가 0이 되면 if 문이 실행이 되지 않는다. 그렇기 때문에 페이스북의 비용은 빈칸이 된 것이다. 그렇다면 페이스북 비용에 다른 값을 넣고 싶다면 어떻게 해야할까?
df에서 sheet1으로 바뀐 부분과 어떤건 sheet2로 바뀌었습니다. 차이가 무엇일까 살펴보면, 우리가 비교하려는 값은 sheet1에서 뽑아줍니다. 그리고 비교하려는 값으로 얻는 것은 sheet2에서 찾기 때문에 col_E (원하는 것 = 원하는 매체 노출수에 따른 '가격')는 sheet2에서 조건을 걸게 된 것입니다.
그리고 우리는 sheet1 '비용' 컬럼을 채워야하기 때문에 sheet1['비용'][i]에 sheet2에서 받아온 '가격'을 입력하게 됩니다. 애초에 두 시트의 컬럼명이 '가격'이었으면 덜 헷갈렸을 수도 있는데, 어떤 부분을 체크해야하는지 알려드리기 위해서 일부러 다르게 사용했습니다. 코드는 작업하기 편하게 사용하시면 됩니다.
데이터가 몇개 되지 않으면 INDEX/MATCH 함수나 VLOOKUP 함수를 엑셀에서 돌려도 시간이 얼마 안 걸립니다. 하지만 데이터가 많아지면 많아질수록 웬만한 사무용 컴퓨터에서는 엑셀이 버벅입니다. 조금이라도 도움이 되셨으면 좋겠고 다음에는 엑셀을 파이썬으로 구현할 때 사용했던 기능들에 대해서 소개하겠습니다.
회사내 보안이 심하지 않으면 목차 1, 2번은 아마 안 보셨을거라 생각합니다. (운이 좋은 경우) 3편에서는 실무에서 TOP3 안에 드는 엑셀 함수 VLOOKUP 사용법, 유용한 함수들을 파이썬으로 구현하는 방법에 대해서 소개하고자 합니다. 엑셀을 제대로 사용해보지 않은 신입들도 브이룩업?이라고 많이들 들어보셨을텐데 실무에서 엄청 사용하는 것 같습니다.
솔직히 제목 어그로를 어떻게 끌까 하다가, 파이썬 엑셀 사무 자동화라는 타이틀은 빼버리고 필요한 키워드들만 넣었습니다. 단순 조회수를 위해서가 아닌, 저처럼 효율충들을 위한 글입니다. 한 번 사용해보세요 제발...
네이버에서 이런 캐릭터와 함께 오늘은 ~하는 방법 알아볼까요? 하고 특별한 정보도 없이, '그냥 그렇다고 하네요~' 로 끝나는 글들을 혐오해서 유용하지 않으면 욕하셔도 됩니다. 저도 사수 분이 엑셀을 VLOOKUP 사용법과 데이터 전처리하는 방법들을 알려주셨는데, 수작업이 너무 심하고... 데이터가 많다 보니 VLOOKUP이나 다중 조건 함수를 처리하는데 시간이 너무 오래 걸렸습니다. 결국 답답해서 파이썬으로 해결했습니다.
서론이 길었는데 엑셀에서 함수를 처리하는데 멀뚱멀뚱할 동안, 파이썬은 작업을 완료할만큼 속도도 빠르고 시간도 단축된다는 것.
데이터가 적으면 VLOOKUP 함수를 사용하면 얼마 안 걸린다. 하지만 조건이 하나 둘씩 붙어서 다중 조건이 되고, 데이터가 몇 천개 ~ 몇 만개 정도 되면 시간이 기하급수적으로 늘어난다. 다중 조건 INDEX MATCH 조합을 사용했을 때 컴퓨터가 느려서인지 시간이 정말 오래 걸렸다. 하지만 파이썬에서는 다중 조건을 여러번 사용했음에도 몇분도 안 돼서 작업이 완료 됐다.
키워드 : #다중조건, #여러시트, #여러값가져오기
VLOOKUP
이미 아시겠지만 VLOOKUP은 (비교값, 비교대상 범위, 결과를 가져올 열 번호, 옵션)을 활용하지만, 기준값의 우측 데이터만 가져올 수 있다. 하지만 좌측 데이터를 가져오려면 #N/A가 뜨면서 오류가 난다. 다중조건을 사용하기 쉽지 않아서, 많은 분들이 INDEX MATCH를 사용한다. 다른 시트에서 값을 찾으려면 범위 앞에시트명!을 붙인다. EX) =VLOOKUP($A2, 시트명!$A:$C, 2, FALSE)
INDEX MATCH
INDEX 함수를 사용하여 특정 위치에 해당하는 값을 가져오고, MATCH를 사용해서 기준값이 어디에 위치하는지 정보를 얻을 수 있다. 실무에서 이 두 함수를 조합하는 것으로 보인다. 대부분 옵션은 0이나 FALSE가 들어가는데 정확히 일치한다는 뜻으로 쓰인다.
-INDEX (검색범위, 행번호, 열번호)
-MATCH (찾는 값, 검색범위, 옵션)
-MATCH (1, (첫번째 조건)*(두번째 조건), 옵션)
ㄴ 조건이 충족하면 1(TRUE) 아니면 0(FALSE), 곱해서 1이 되는 조건을 찾는다로 이해하시면 됩니다
*파이썬으로 진행되기 때문에 파이썬(3.7기준), 주피터노트북, pandas 모듈 필수 설치 (csv로 진행)
이걸 어떻게 설명을 할까 생각하다가 직접 보여주는게 좋을거 같아서, 임시로 데이터를 만들었습니다. 오해는 말아주세요. 그리고 파이썬에서 VLOOKUP과 INDEX MATCH 사용법이 비슷해서 INDEX MATCH 기준으로 설명드리겠습니다.
매체별 노출수에 따른 비용을 구하려고 할 때 엑셀 함수로는 =INDEX($J:$J,MATCH(1,($H:$H=$A2)*($I:$I=D2),0),1) 이런 식으로 구하면 별 문제 없이 5000, 7000, 30000, 11000이 입력이 될 것이다. 그렇다면 이것을 어떻게 파이썬으로 구현할까?
1. 파일 불러오기
1
2
3
4
import pandas as pd # pandas가 없으면 터미널에서 pip install pandas
df = pd.read_csv('위치/파일명.csv', encoding='utf-8-sig') # 직접 불러오기
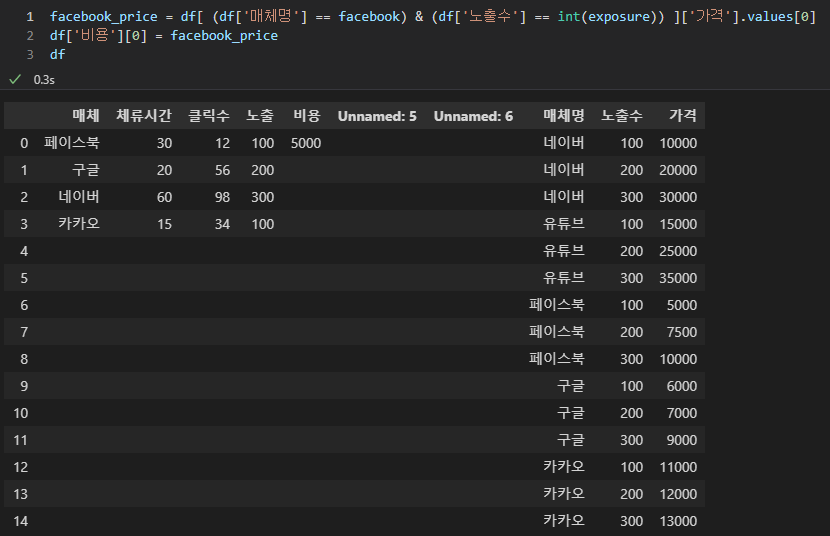
방금 구한 값을 facebook_price라고 칭하고, '비용' 컬럼 0번째 인덱스에 집어넣겠다는 것입니다. 그런데 facebook_price 끝 부분 '.vlaues[0]'은 유의하셔서 보셔야 합니다. 만약에 매체가 페이스북이고 노출 400인 값이 들어왔을 때 비용을 구할 수 없기 때문에 #N/A 값이 생기는 것처럼 파이썬에서도 에러가 납니다.
그렇다면 이 에러를 어떻게 잡을 수 있을까요?
다음 편에 이어서 작성하겠습니다. 원래 여러 내용을 같이 작성하려고 하였으나, 이 게시물을 읽으실 분들은 아직 파이썬이 능숙하지 않으실 것 같아서 우선 위에 내용부터 이해하면 좋겠네요!
정리
VLOOKUP => df [ df['열 이름'] == A2] ['구하고자 하는 값이 있는 열 이름'].values[0]
INDEX/MATCH = > df [ ( df['열 이름1'] == A2 ) & ( df['열 이름2'] == B2 )] ['구하고자 하는 값이 있는 열 이름'].values[0]
조건이 추가 되면 df [ (기존 조건) & df['열 이름3'] == C3 ] 안에 &와 함께 조건을 추가하면 됩니다.
전 글에서 pip install 문제 때문에 ipykernel이 설치가 안 돼서 print(1)도 되지 않았다. 이후 문제를 해결하고 1이 출력 됐을 때의 기쁨은 엄청났다. 하지만 그 기쁨도 잠시뿐. 행복한 마음으로 csv 데이터 파일을 열었더니 오류가 이렇게나 길게 나왔다.
문제는 UnicodeDecodeError: 'utf-8' codec can't decode byte 0x9b in position 32: invalid start byte 라고 한다. codec 문제라고 하는데, 예전에도 이런 문제와 부딪혀 봐서 금방 해결할거라 생각했다.
encodig = 'utf-8' / 'euc-kr' / 'cp949' / 'utf-8-sig' 이 중에 한 놈이라도 걸려라 했는데, 한 명도 걸리지 않았다. 그 어떤 것도 되지 않아서.. csv 파일이 문제라고 생각해서 xlsx 확장자를 열어봤는데
ValueError: Excel file format cannot be determined, you must specify an engine manually. 라는 에러 메시지가 출력됐다. 그래서 또 열심히 구글링을 하기 시작했는데 도움이 되지 않았다. 그래도 참고하실 분은 봐주세요.
저는 xlwings 대신에 pd.read_clipboard()를 사용하였습니다. 이게 참 훌륭한 기능이라는 걸 깨달았네요. 그냥 가져오고자 하는 데이터를 드래그해서 복사하시면 dataframe이 만들어집니다. 자동으로 행, 열도 생성되고 이거 아니었으면 자동화는 힘들었을거 같네요 ㅠㅠ
그리고 이걸로 긁어와서 만든 파일의 경우 세션(?)이 끊기기 전까지는 csv로 불러서 읽을 수 있습니다! 다만 csv 파일을 열어서 수정을 하게 되면 다시 못 쓴다는 치명적인 단점이... 그래도 수작업을 할 시간에 코드로 자동화를 한다면 훨씬 더 편하니까 이렇게 삥삥 돌아서 갑니다.
카테고리 분류 작업을 포함한 수작업이 많아서, 파이썬 응용AI 교육과정에서 900시간 배웠던 파이썬을 써보기로 했다. 우선 보안이 훌륭한 회사에서는 사내망에서 접속을 차단한 사이트들이 많다. Visual Studio Code(비쥬얼 스튜디오 코드)를 다른 팀에서 쓰고 있어서 vscode는 괜찮다는 것을 알았다. 그리고 다행히 python.org 는 접속이 가능했지만, 아나콘다(anaconda)는 접속이 차단 됐다.
우선 파이썬을 설치하고 비쥬얼 스튜디오 코드를 설치했다. 확장 기능들을 추천하자면
-pyhthon (기본)
-jupyter (기본)
-Korean(사용법) Language Pack for Visual Studio Code (기본)
-Visual Studio IntelliCode (feature 들을 추천해줌)
-Python Indent(들여쓰기 할 때 위치 구분)
-Python Docstring Generator
기타 필요 기능들은 검색
1
2
3
4
5
6
7
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x0000027DE1695D88>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/google-image-download/
WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x0000027DE16A65C8>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/google-image-download/
WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x0000027DE16A6CC8>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/google-image-download/
WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x0000027DE16AD408>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/google-image-download/
WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x0000027DE16ADB08>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/google-image-download/
ERROR: Could not find a version that satisfies the requirement google-image-download (from versions: none)
ERROR: No matching distribution found for google-image-download
아나콘다로 모듈들을 설치하면 더 편리한데, 그래도 pip install로 설치가 가능하니 문제가 없겠거니 생각했다. 그런데 파이썬을 설치하고 vscode까지 설치를 했는데 ipykernel이 설치가 되지 않았다. juptyer notebook을 활용하려고 했으나 실패했다.
이런 느낌의 오류와 함께 ipykernel이 없다는 식의 경고창이 떴다. 그래서 어떤거 문제일까 열심히 찾았는데 답이 없었다.
검색을 해보니 보안 인프라가 갖추어져 있기 때문에, pip 같은 패키지 매니저로 제대로 작동이 안 된다는 느낌? 그래서 프록시 서버를 무조건 신뢰한다는 옵션을 넣어서 설치하면 된다고 하는데.. 만약 위 링크들에서 해결이 되면 다행이고 안 되면 다른 방법을 소개해드리려고 한다.
우선 이 과정을 하기 전에 회사 IT팀과 연락을 필수로 해야한다. 원격으로 어떤 문제가 있는지 확인을 해봤는데, 목적지 IP 대역이 너무 많아서 정확한 목적지 IP대역 확인이 불가능하다는 결론이 나왔다. 목적지 IP/port를 알 수 있다면 방화벽 신청을 하면 되지만 이건 불가능했다.
그래서 임시방편으로 테더링을 추천해주셔서 그렇게 했다. 안 되면 핫스팟으로 pip install을 해보면 된다. 혼자서 파이썬을 설치하려고 하니.. 기본 구축이 왜 이렇게 어렵고, 에러가 많이 나지? 좌절했는데 알고보니 회사 프록시 서버 문제여서 황당했다. 이후에는 별다른 문제 없이 모듈들이 잘 설치 됐고 작업을 진행할 수 있었다.
사내망 막힌 사이트 볼 수 있는(뚫을 수 있는) 팁을 드리자면, 구글에서 사이트 주소 옆에 거꾸로된 삼각형을 클릭하여 저장된 페이지를 클릭한다. velog.io 사이트나 간혹 아예 차단이 된 사이트는 열리지 않는다. 그래도코드를 혼자 짜다보면 무한 에러가 나기 때문에 구글에서 이렇게라도 검색할 수 있어서 다행이다 ㅠㅠ
하지만 더 큰 문제가 있었으니... 파이썬에서 엑셀, csv 파일들을 읽을 수 없었다. 진짜 산 넘어 산
336x280(권장), 300x250(권장), 250x250, 200x200 크기의 광고 코드만 넣을 수 있습니다.
정말 속전속결이었다. 이렇게 빨리 합격 소식과 함께 출근하게 될 줄은 몰랐다. 이틀만에 서류전형 합격소식이 왔고, 3일 뒤에 면접을 볼 수 있냐는 말에 면접도 기회라서 보게 됐다. 면접을 봤을 때 어느 정도 느낌이 있었지만 면까몰이라고 했으니 기다리고 있었다. 면접 본 다음 날 합격했다고 전화가 와서 바로 준비를 했다.
오랜만에 면접을 봐서 그런지 어떻게 해야할까 질문도 찾아보고, 유튜브도 다시 보게 됐다. 그런데 나 같은 경우는 그럴 필요가 없었다... 이건 뒤에 가서 얘기를 하고 그래도 면접 질문이 궁금해서 찾아오신 분들이 있으니 정리한 걸 공유하려고 한다.
마케팅, 데이터, 기획 쪽 직무?
1. 자기소개 2. 지원동기 3. 펑타이 코리아에 대해서 4. 광고대행사 무슨 일 하는지 5. 지원한 포지션에 뽑혀야 하는 이유 or 강점 6. 성격 장·단점 7. 엑셀, 기본적인 문서 작업 수준 8. 어떤 식으로 스트레스 푸는지 9. 광고대행사의 야근에 대해 어떻게 생각 10. 어떤 동료, 상사와 일하고 싶은지
요즘 내용이 많이 바뀌어서 자소서 관련 부분 팀프로젝트 관련 필히 준비하세요~
*자소서 기반 질문 위주라서 준비해야 한다
열심히 면접왕 이형 1분 자기소개서 보고 연습 했는데, 나는 자기소개도 건너 뛰었다. 그냥 면접관님(팀장님)이 단도직입적으로 자소서에 쓴 내용 때문에 면접 꼭 면접 보고싶었다고... 말하기는 민망하지만 블로그에 쓴 글과도 연관이 되어있다.
그래서 어떤 식으로 그런 결과를 낼 수 있었는지 여쭤보셨다. 그쪽 관련해서는 엄청나게 다양한 시도를 하고, 경험을 직접 해봐서 술술 대답을 할 수 있었다. 반복해서 하는 일인데 괜찮냐는 말과 함께 6개월 동안 하는 직무니까 중간에 그만두지는 않을 거죠?라고 하셔서 '아, 이건 된건가..?' 싶었다. 추가로 경험했던 부분이 퍼포먼스 마케팅을 직접하고 있었다는 식으로 얘기를 해주셨다. 데이터 관련직무인데 인사이트를 가지고 있어서 뽑힌게 아닌가하는 생각이 들었고, 들어가서 어떤걸할지 많이 궁금했다.
엑셀이나 기본적인 문서 다루는 걸 물어보셨으면... 파이썬으로 자동화 해보고싶다고 말씀드리고 싶었는데, 물어보시지는 않았다.
그렇게 일주일만에 모든 절차가 끝나고 합격을 했다. 그리고 지금 출근한지 몇 주가 됐는데.. 현재는 인수인계를 하고 있기도 하고, 일이 5~6월이 몰린다고 해서 할게 많지는 않다. 데이터를 다루고, GA로 데이터를 뽑는 걸 반복해서 한다고 했는데 아직은 제대로 보지는 못 했다.
그런데 예상했던 것과 달리, 펑타이는 수작업이 많아 보인다. 그래서 인턴을 많이 뽑는다는 말이 있을 정도.. 제일기획 자회사다 보니 그만큼 일이 많아서기도 하다. PTKOREA로 회사 상호명이 바뀌었습니다.
회사생활
회사는 자유롭다. 수평적인 가운데 서로 영어 호칭을 쓴다. 복장도 진짜 자유롭다. 처음에 세미 정장느낌으로 입고 갔는데 그럴 필요가 없었다. 블라인드에서는 여름에 반바지도 입을 정도라고.. 간식도 많고, 자율 출퇴근제라서 편하게 다닐 수 있다.
지금 그래서 무슨 일을 하냐고 물으면, 성격상 수작업이나 효율 떨어지는 일을 싫어서 업무 자동화를 시도하고 있다. 진짜 제약이 너무 많기는 하지만 ㅋㅋㅋㅋㅋ 꿋꿋이 하고 있다. 엑셀 MATCH, VLOOKUP 이런 함수를 다 파이썬으로 만들고 있다. 노트북도 좋은게 아닌데 엑셀 함수를 돌리면 거의 하루종일 걸리는 듯 해서 파이썬으로 코드를 짜고 있다(95% 이상 완성). 추가로 크롤링과 자동 캡쳐까지하고 시도하고 있다... 데이터를 어떻게 저장할지, 어떤 규칙으로 분류할지 많은 생각을 하게 된다.