
6-1 파이널 프로젝트 : 자연어처리, kogpt2를 이용한 슬로건 생성
목차 1. SKT-AI/KoGPT2와 자연처(NLP) 2. 데이터 전처리 (나무위키, 블로그) 3. KoGPT2와 기능구현 (인풋 아웃풋 조정) 4. 짧은 텍스트 / 문장유사도 5. 배포 (구글 애즈, GA, AWS) 모바일로 보니 너무 불편해서.
0goodmorning.tistory.com
분명 8월 중순 쯤에 임시저장한 글인데 파이널 프로젝트와 1일 1깃을 도전해본다고 글 쓰는 것이 느려졌다. ko-gpt2 관련된 글 유입이 늘기 시작하면서.. 구글에서도 노출될만한 글들을 추가로 쓰면 좋을 것 같아서 먼저 GPT-3 사용법과 설치 방법, 시크릿 키를 받는 방법을 간단하게 설명하고자 한다. (completion, classify text, search, answer questions 등이 가능하다.)
https://share.hsforms.com/1Lfc7WtPLRk2ppXhPjcYY-A4sk30
share.hsforms.com
GPT3가 처음에는 무료였다가 작년부터 유료가 돼서, 무료로 사용하려면 시크릿키부터 받아야 한다. 시크릿키는 위 링크를 타고 들어가면 되는데 간단한 인적사항을 입력하면 된다. 이게 사람마다 다른데, 짧게는 하루에서 길게는 몇 주까지 걸린다고 하니 추천 방법으로는 여러 메일을 통해서 신청을 하자. 그리고 모델 생성? 모델 불러오는 횟수도 1달에 10번정도로 제한되어 있으니 미리 여러 개로 신청을 해놓자.
그리고 이번에 국립국어원에서 인공지능 능력평가를 한다는데, baseline model로 'ko-gpt-trinity-1.2B-v0.5'을 사용한다. 아직 베타버전인거 같은데 SKT에서 GPT-3 아키텍처를 복제하여 설계된 transformer model이라고 한다. 파이토치 모델.bin 파일만해도 4기가 넘는다... 어떻게 불러야할지 몰라서 일단 KoGPT3라고 하는데 아직 사용방법은 모르겠다.
OpenAI API
An API for accessing new AI models developed by OpenAI
beta.openai.com
OpenAI GPT3는 친절하지 않다. 가이드라인이 있긴 하지만 처음에는 헷갈린다. 그리고 중요한건 우리가 직접 조정할 수 있는 값들이 많지 않다. 결국 데이터를 잘 정제하고, 효율적으로 넣어야 좋은 결과값들이 나온다.

WSL2(Windows Subsystem for Linux 2) 설치 및 사용 방법
지난 5월 윈도우10의 대규모 업데이트가 있었습니다. 이번 업데이트에는 WSL2 정식 릴리스가 포함되어있습니다. WSL은 경략 가상화 기술을 통해 윈도우에서 리눅스 배포판을 사용할 수 있게 도와
www.44bits.io
우선 파인튜닝을 위해서 우분투를 설치해준다. 링크를 따라가면 쉽게 설명을 해주고 있어서 대체한다.
설치를 했으면 windows PowerShell에 들어가서 Ubuntu를 실행한다. 우선 파이썬이 깔려있는지 보기 위해서 $ python3 --version을 확인한다. 파이썬이 없으면 파이썬을 설치한다. $ sudo apt-get upgrade python3

$ pip install --upgrade openai 를 입력하여 openai를 설치한다.
$ export OPENAI_API_KEY="시크릿 키" 입력한다. 아무런 반응이 없는게 정상이다.

이런 형식으로 jsonl 로 만들어주면 되는데, 인풋 데이터(prompt)와 아웃풋 데이터(completion)를 어떻게 할지 잘 정해야 한다. 그래야 나중에 결과값이 좋아진다 ㅠㅠㅠ
cd를 사용해서 jsonl을 만들어줄 파일이 있는 위치로 간다.
$ openai tools fine_tunes.prepare_data -f 파일이름.확장자

그러면 창에서 파일을 분석해준다. 본인의 파일에 따라서 내용이 달라지니 어떤 항목을 Y로 할지 N로 할지 정해야 한다.

Based on the analysis we will perform the following actions:
- [Necessary] Your format `CSV` will be converted to `JSONL`
- [Recommended] Remove 4 duplicate rows [Y/n]: y
- [Recommended] Lowercase all your data in column/key `prompt` [Y/n]: y
- [Recommended] Add a suffix separator ` ->` to all prompts [Y/n]: n
- [Recommended] Add a suffix ending `\n` to all completions [Y/n]: n
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: y
Your data will be written to a new JSONL file. Proceed [Y/n]: y
jsonl 파일이 완성이 됐다. 이제 파인튜닝을 할 차례다.
$ openai api fine_tunes.create -t "생성된 파일 이름.jsonl" -m curie
마지막 curie는 base_model인데 ada, babbage, curie가 있는데 curie가 성능이 더 좋다고 들었다.
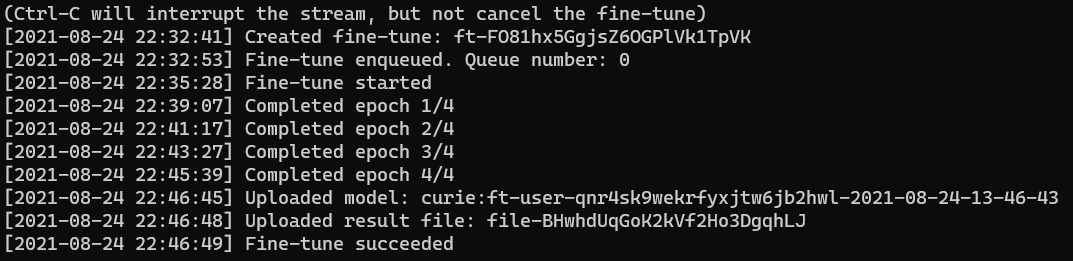
openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>
자신의 파인튜닝된 모델 이름이 표시가 된다. 잘 기억해야 한다. 나중에 jsonl 파일로 만들어진 모델인지 헷갈릴 수가 있다. 그리고 문제가 되는 부분은 본인의 시크릿키에서만 파인튜닝한 모델이 작동이 된다.

openai api completions.create -m curie:ft-user-본인의모델이름 -p 인풋데이터
이렇게 결과를 확인할 수 있다! 뭔가 결과가 잘 안 나왔는데 여러번 확인하면 더 좋은 결과가 나올 것으로 보인다.
gpt3.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
https://colab.research.google.com/github/kes76963/myproject/blob/main/gpt3_edit.ipynb
계속 우분투에서 활용할 수 없기 때문에, 파인튜닝한 모델을 구글 코랩에서 사용하는 방법은 위 링크를 따라하면 된다. 생각보다 좋은 결과값은 안 나오는 것 같다. GPT3 활용 사례들을 보면 압도적인 결과물들이 나오는데, 더 괜찮은 모델을 써서 그런건지.. 아니면 gpt2랑 토크나이징 방식이나 훈련 방법이 달라서 그런건지.. 모델을 뜯어볼 수가 없어서 약간 답답한 느낌이다.
마무리는 gpt3 사용방법을 알려주는데 도움을 준 분께서 만드신 동화이야기 영상입니다.