11번가 답게 11월 11일까지 원서를 접수 받았다. 그리고 13일에 시험을 바로 보고, 11일 뒤인 24일에 결과 발표가 나왔다.
자소서 질문
-활용 가능한 프로그래밍 언어/기술/개발Tool 등을 키워드로 작성해주세요.
-지원직무를 선택한 이유에 대해 설명하고 이를 위해 어떠한 노력을 하였는지 소개해주세요.
-도전적인 목표를 설정하고 지속적인 몰입을 통해 성장한 대표적인 경험에 대하여 소개해주세요.
-공동의 목표달성을 위해 상호신뢰와 소통을 바탕으로 협업을 진행한 사례에 대하여 역할과 기여 중심으로 소개해주세요.
지원할 수 있는 직무가 SW개발, 검색모델링, Machine Learning 이렇게 3가지로 나뉘었는데 직무 내용을 보니 검색모델링이 더 적합한 것 같아서 검색모델링쪽으로 지원했다.
2019년에 올라온 채용 영상을 보면 '이 직무는 이런 일을 하는구나'를 느낄 수 있어서 꼭 보고 지원하면 도움이 될 것으로 보인다. 저때는 검색추천이 있었는데 직무간 변화가 있었던 모양이다.
ML쪽은 이미지 검색, 카탈로그 자동 생성쪽이었고, 검색모델링이 조금 더 NLP쪽이라 진행했던 프로젝트(카테고리 분류, 추천, 검색 기능 개선)와 비슷했던 것 같다. 사실 지원 인원이 더 적었다.
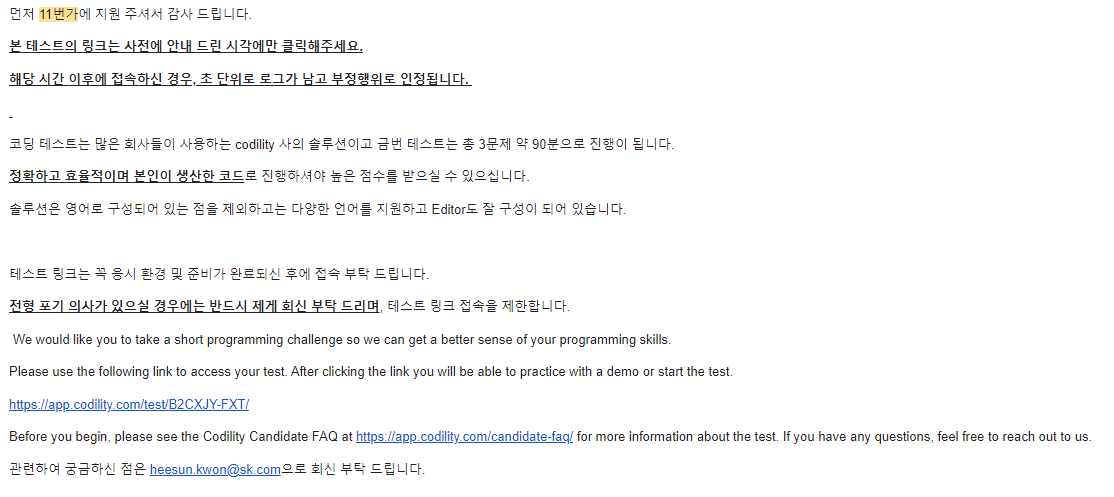
다른 곳과 다르게 코딩테스트(코테)는 프로그래머스로 하지 않고 코딜리티(codility)로 진행을 했다. 부정행위 적발에 대한 얘기도 없을 뿐 아니라 별도 IDE를 사용할 수 있어서, 약간 본인의 양심에 맡기는 듯 했다. 그리고 문제는 영어다.
코딜리티는 처음이라서 사이트에서 어떤식으로 문제가 나오는지 연습을 했다.
1. Iterations lesson - Learn to Code - Codility
Find longest sequence of zeros in binary representation of an integer.
app.codility.com
회원가입을 하고 문제를 풀어볼 수 있다. 히든 케이스도 히든 케이스지만... 시간 복잡도(O)를 중요시 여겼다. O^2가 되면 효율이 엄청 떨어지는 것을 확인할 수 있다. 솔직히 알고리즘도 아직 이해가 안 됐는데, 시간 복잡도 개념은 더 생소했다. 어떻게 하면 효율적으로 풀 수 있을지를 한 번 더 생각해야 했다.
이전에는 백준을 풀었는데 이번에 코딜리티를 풀면서 깨달았던 점은, 예전에 했던 토이 프로젝트들 코드가 진짜 최악의 효율을 가지고 있다는 것... 데이터가 적었으니 괜찮았지, 데이터가 많아지면 시간이 엄청 걸리겠구나라고 느꼈다. 그리고 for문 2번 돌리면 될 것을 왜 이렇게 복잡하게 해야하나 싶기도 했다 ㅋㅋ
하여튼 11번가 코딩테스트 난이도 후기를 찾아봤는데, 사람들이 대부분 쉽다고 얘기했다.. 알고리즘, 구현도 다른 코테보다 쉽고, 복잡한 알고리즘도 안 나온다고...

결과는 당연히 떨어졌지만 약간 당황스러웠다. 11번가 코테가 끝나고 프로그래머스를 풀었는데 2~3 레벨에 비해, 문제가 어려운 편은 아닌 것 같았다. 그런데 시간대별로 각각 다른 직무의 사람들이 시험을 봐서, 앞에 S/W 직무 사람들의 후기를 들었을 때 대부분 문제가 너무 쉽게 나왔다고 했다. 1~2줄이면 가능하다부터, 시간복잡도가 이렇다 저렇다.
후기를 보고 별 걱정 없이 1시간 30분짜리, 3문제를 봤다. 그.런.데 딱 첫번째 문제부터 간단하게 나올 문제가 아니었다. 구현이었는데 조금은 생각해야할 문제였고, 마지막 문제는 조금 이해가 힘들었다. 테스트 케이스를 하나 더 줬으면 좋지 않았을까 싶었는데 1개만 주어졌다. 2번 문제는 코딜리티 예시 문제와 비슷해서 금방 풀었다.
1번 문제는 테스트케이스가 다 맞았지만, 아마 히든 케이스에서 틀릴 것 같은 예감이 있었고, 3번 문제는 거의 손도 못 대고 끝났다. 좀 아쉬움이 남는 코딩테스트 ㅠㅠ 실력을 더 키워야겠다.
'코테 & 취준' 카테고리의 다른 글
| PTKOREA 인턴 면접 합격 후기 및 인턴 생활 정리해 드림. (마케팅, 데이터) (4) | 2022.01.18 |
|---|---|
| CJ올리브네트웍스 AI Engineer 인성/ 코딩테스트(코테) 후기 (9) | 2021.11.21 |