336x280(권장), 300x250(권장), 250x250, 200x200 크기의 광고 코드만 넣을 수 있습니다.
유튜브로 새로운 수익모델을 찾기위한 채널 분석을 시도하고 있다. (기존 채널에 영상을 새로 올려야 하는데 요즘 못 올리고 있다 ㅠㅠ) 솔직히 노가다를 해도 되는데 파이썬을 배웠으면 자동화를 하는게 맞지 않을까 싶고, 재밌는 실험들을 해보고 싶어서 코드를 짜고 있다.
셀레니움으로 페이지 자동 번역, 키 입력 정보가 필요하신 분들은 밑으로 내려주세요!
진행할 목록
- 페이지 성별 분석 (이름 데이터셋 수집 완료, CNN 카테고리 분류 완료, 검증 단계) => 얘 때문에 자동번역이 필요했음
- 페이지 연령 분석, 댓글 문체로 분류 도전 (자체 유튜브 조회수 100만 영상들에서 댓글 크롤링 후, 연령, 성비 분석 후 학습)
- 댓글로 영상 주제 분석 (긍정, 부정, 어떤 반응으로 영상이 화제가 됐는지 체크)
- 어그로 확인 (같은 주제, 같은 업로드 날짜 => 왜 다른 조회수? 썸네일, 키워드)
셀레니움 자동 번역 필요했던 이유?
연령대가 있는 층들은 대부분 유튜브 계정 닉네임이 본인 이름으로 되어 있어서 성별 분석하기가 조금 수월해 보였다. 하지만 영어로 이름을 입력하신 분들도 있어서 이걸 자동으로 번역해서 닉네임을 크롤링 해야 했다. 문제는 셀레니움으로 자동 번역이 잘 되지 않았다.
-파이썬에서 셀레니움 웹 사이트 언어 변경
-Translate the webpage opened via Selenium Webdriver to English
-Translate webpage language using Selenium
-Select an Option from the Right-Click Menu in Selenium Webdriver
-Modifying the language option in selenium
이렇게 다양하게 검색을 했는데도 문제가 잘 해결 되지 않았다. (구글이 PageRank를 활용한 알고리즘이라고 하는데 SEO 시스템을 잘 몰라서 외국에서 검색이 될지는 모르겠지만 그래도 찾아주시는 분들은 도움이 됐으면 좋겠다.) 일단 시도했던 것들에 대해서 간단하게 보여주자면
translate_whitelists에서 en -> ko로 바꿔주면 된다고 친절하게 설명이 되어있는데 이것 또한 되지 않았다. 그래서 영어권에서는 2번, 3번 방법의 경우를 추천했는데 이것 또한 되지 않았다^^
그래서 생각한 방법이 오른쪽 마우스로 번역하면 되겠거니 싶었다. 마우스 좌표 값을 설정해서 오른쪽 버튼을 클릭하기 번거로워서, 키보드로 마우스 오른쪽 버튼을 누르는 방법이 있나 찾아보니 shift + f10이라고 구글에서 친히 알려주신다. 그리고 Translate에 'T' 앞 글자를 따서 단축키를 만들지 않았을까 하고 T를 눌러보니 번역이 됐다!
그리고 send_keys(Keys.SHIFT + Keys.F10 + 't')를 해봤더니 t가 눌리지 않았다. 이런...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from selenium.webdriver.common.action_chains import ActionChains
ctrl + f, shift + a 처럼 '페이지 내 검색어 찾기', '전체 선택'같이 셀레니움에서 번역이 아닌 단순 키 입력을 원하시는 분이라면 1번 방법을 사용하시면 됩니다. 이것도 안 돼서 더 찾아보니, ActionChains를 활용하면 된다고 해결책으로 제시했는데 이것도 되지 않았다.
드디어 파이널 프로젝트 글도 마무리 ㅠㅠㅠ 프로젝트 중 안 좋은 일이 있어서 서비스 배포 기간에 참석을 하지 못 했다. 원래는 GPT3를 활용하여 기업 설명을 완성시켜주는 서비스도 만드려고 했으나 불가능했고, 프로젝트 이후에나 GPT3를 다뤄봐야겠다고 생각했다.
서비스 이름도 조금 더 찰떡 같은 이름을 지으려고 했으나 막상 지어보니 별로라서 그냥 그대로 유지했다. copylight (카피의 한 줄기 빛이 되다.) copyfast (카피를 빠르게! - 근데 패스트 발음을 하면 전염병 의미가 있어서 패스), copydai (ai로 카피 만들기 좋은 날 카피데이) 등등 ..
예전에 카피라이팅에 도전을 많이 했었는데 아무리 생각해도 언어유희나 임팩트 있는 문구를 창작하는 건 재능이지 않을까 싶다. 노력으로는 되지 않아서 우리가 만든 것이 인공지능 카피라이팅이 아닐까?
Django를 이용해 웹 구현을 했고, 나는 디자인 부분에서 조금 도움을 줄 수 있었다. 원래는 로딩창 부분에서 Tip이나 튜토리얼 부분을 gif로 만들어서 심심하지 않게 하려고 했다. 하지만 장고 개발하던 팀원이 좀 무리지 않냐고 해서 수용했다.
추가적으로 장고로 로컬을 이용한 연결이 끝이 아닌, AWS를 통해 인스턴스를 생성하여 우분투 서버를 사용하여 웹 서비스를 배포했다. 파파고로 한국어를 영어로 자동 번역하는 서비스도 있었는데 여기서 API 키를 그대로 노출시면 안 되다고 해서.. 중간에 과정이 많이 있던 걸로 기억한다.
그리고 aws에서 얻은 탄력적 ip주소를 사용하여 접속하는 것 보다 도메인 주소를 지정하여, 서비스 내용을 알 수 있게끔 가비아 사이트를 이용해 도메인을 연결하였다. 나중에 서비스 이름을 바꿀 수도 있어서 간단하게 990원짜리를 이용하였다.
예전에 유튜브를 보면서 이 부분은 꼭 해봐야겠다 생각이 들어서, GA와 구글 애즈를 사용해야 된다고 강력하게 주장했다. 이유를 설명하자면 국비지원 교육의 단점에 대해서도 잠깐 얘기를 해야하는데.. (검색을 하고 우연히 들어오시는 분들을 위해서 적어두겠습니다.)
- SSAFY처럼 커리큘럼이 체계적이지 않고, 생각보다 몇몇 강사분들은 전문적이지 않다.
- 포트폴리오용 토이프로젝트를 많이 진행하는데 이걸로는 메리트가 없어보인다. 본인이 해야한다. 공부든 뭐든 원래 그렇듯이
(학부생이나 관련 개발자들은 최소 몇 개월에 걸쳐서 프로젝트를 진행할텐데, 고작 일주일의 프로젝트로 뭐를 했다고 할 수 있을까?)
위 유튜버의 말대로, 남들 다 하는 토이프로젝트에서 남들과는 차별점을 둘 수 있는 것이 배포를 해보고, 유저의 피드백이나 오류들을 개선하는 과정이지 않을까 싶다. 그리고 유저의 피드백을 받기 위해서 구글 애즈로 현업자들 상대로 광고를 집행해 노출도 시키고, 직접적인 피드백 받기가 어려우면 GA로 어떤 페이지에서 오래 머물렀고, 이탈이 있었는지 등을 분석하면 좋을거라 생각했다.
광고 캠페인 집행 : 유튜브와 구글에서 검색을 통해서 금방 제작이 가능했다. 물론 효율적인 광고를 위해서는 세부적으로 다뤄야할 부분들이 많았다. 처음 광고를 해봐서 그런지 약간 돈만 날린 부분도 있었고, 다른 광고 캠페인들처럼 전환이 이뤄졌다할만한 결과가 없기 때문에 성과 측정은 어려웠다.
구글애널리틱스 자격증은 혹시나 필요할까봐 따긴 땄는데, 직접 이런 식으로 통계를 본 적은 처음이다. 물론 유튜브로 구독자 분석, 채널 분석을 많이 하긴 했지만 그거와는 조금 다른 분야였다. GA 코드는 <head> 태그 바로 뒤에 복붙하면 됩니다. 이것도 GA 자격증을 따기 위해서 나오는 문제중 하나입니다. ㅋㅋㅋ
원래는 사이트 주소를 오픈하면 좋은데, 현재 서버에 문제가 좀 있어서 수정중이라고 들었습니다.
앞으로 할 부분은 자연어 공부를 조금 더 하면서 유튜브 채널, 구독자 분석을 진행하려고 합니다. 감사합니다.
KoGPT2로 슬로건, 광고문구를 생성하고 이를 어떻게 개선할 것인가에 대해서 이어서 작성하겠습니다. 처음에 포스팅 하나에 넣으려고 했는데 생각보다 길어져서 나눴습니다. 이번 포스팅은 아웃풋과 인풋을 어떻게 조정했는지에 대해서 쓰겠습니다.
짧은 텍스트 / 문장 유사도 찾기
사용 이유 와 목적 : 인풋 데이터에 '금융'과 관련된 설명을 넣었는데, 갑자기 '좋은 일자리 만들어주세요'라는 문구가 뜬금없이 튀어나오게 된다. 데이터가 충분하면 이런 일이 없겠지만 추가로 모을 수는 없어서.. 이러한 결과값들을 최대한 배제하는 방법에 대해서 생각했다.
- TF-IDF, CNN을 활용을 활용한 슬로건 분류
- Word2Vec을 사용해서 자주 등장하는 단어와 유사한 값을 지닌 단어가 포함된 문장을 노출
결과값을 확인 했을 때, 나쁘지 않게 나왔지만.. 이 단어들로이 포함되지 않는 문구를 필터링한다면, 걸러져야할 광고문구보다 괜찮은 광고문구들도 대부분 걸러질 것으로 보여서 다른 방법을 또 고민했다.
텍스트 유사도를 구할 때, 추천 시스템에서 사용했던 TF-IDF, 코사인 유사도를 사용하려고 했다. 하지만 파이널 프로젝트에는 적용하기 힘들었던 이유가 비교할 문장이 길지 않고, 한 문장으로 이루어졌기 때문이다. 프로젝트가 끝나고 현재 Textrank나 문장 요약, 키워드 추출 등을 공부하고 있는데, 이 방법도 적합하지 않은 방법이었다.
그래서 찾게 된 것이 Sentence Transformer다. 그런데 생각보다 구글에는 예시가 많지 않았다. 영어 모델은 유사도 높게 나왔는데, 한글의 경우 위의 사진처럼 '한 남자가'라는 단어가 일치한다고 유사도 94퍼센트가 나오는 아이러니한 현상이 발견됐다. 구글링을 더 하다가 Ko-Sentence-BERT-SKTBERT 모델이 나왔는데 오류 때문에 잘 되지 않았다.
우선 슬로건 문구를 포함한 리스트에서 영어로만 이뤄진 슬로건을 제외해 kor_list를 만들었다. 영어가 포함된 문장의 경우 유사도가 얼추 비슷하게 나왔는데, 영어로만 이루어진 문장은 문장 유사도 성능이 떨어져서 아예 제외시켰다. 이후 한 개를 랜덤으로 뽑아서 유사도가 비슷한 값 5개를 뽑아서 평균을 냈을 때, input_sim과 크기를 비교해서 살릴지 버릴지 고민을 했다.
영어로만 이루어진 문장을 뽑는데 애를 먹었다. isalpha()를 사용하게 되면 영어로만 이루어진게 아니라, 한글이 있을 때도 True를 반환하기 때문에 다른 방법을 사용해야했다. 우선 공백을 없애고, 한글만을 남게한다. 만약 영어로만 이루어졌으면 isspace()함수에서 True를 반환하기 때문에 영어만 포함된 문장을 뽑을 수 있다. 반대로 한글로만 이뤄진 문장이 필요하면 '^가-힣' 대신 '^A-Za-z'을 활용하면 된다.
기업, 제품, 서비스 광고문구를 크롤링했기 때문에, 슬로건 자체에 회사명, 제품, 서비스가 들어가는 경우가 있다. 그래서 이를 별표처리를 해줬다. 여기서 문제가 끝난 줄 알았는데.... 아웃풋뿐만 아니라 인풋 데이터도 조정해야 했다. 토크나이징을 할 때 문제가 있었다. 우리는 손크롤링을 할 때 회사 설명에 주로 명사 위주의 키워드를 넣었는데, 토크나이징을 할 때 띄어쓰기 유무에 따라서 결과값이 많이 달라졌다.
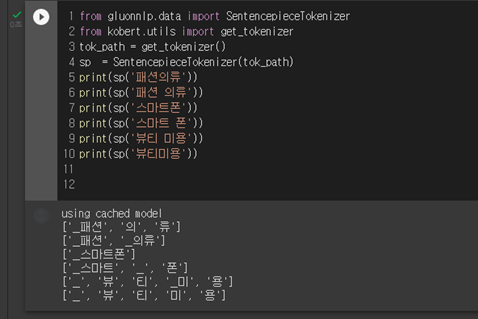
예를 들어 '패션의류'의 경우, 우리는 '패션 의류'를 설명에 입력했는데 토크나이저가 패션(명사) 의(조사) 류(명사) 이런 식으로 인식하기도 하고 제각각 달랐다. 그래서 명사 띄어쓰기 필요성이 느껴져서 형태소 분류를 진행했다. mecab, okt, kkma를 사용해봤는데 전체적인 성능은 mecab이 좋았으나, 명사 추출은 kkma가 조금 더 딱딱하게 잘 끊어냈다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
"""
** 가이드 **
-input_sim
0~15 : 가장 자유로움
15~30 : 자유로움
30~45 : 조금씩 걸러짐
45~60 : 많이 걸러짐 / 강제로 기업 설명을 인식시켜서 더 제한적인 슬로건
60~ : 거의 다 걸러짐 / 슬로건 100개를 했을 경우 유사율 평균 70 이상은 거의 없음
-input_text
최대한 명사 위주의 설명
영어를 쓸경우 뒤에 나오는 단어와 붙여쓰면 더 좋은 결과 ex) 'LED 마스크'보다는 'LED마스크'
"""
input_sim =40# input data 유사성 민감도 지정 / 숫자가 작을수록 관련 없는게 나올 확률이 커짐 / 최소 50이상 설정
input_text ='커피전문기업'
input_text_list = input_text.split(' ') # input data 띄어쓰기로 나누기
이번에도 산 넘어 산이었다. kkma가 딱딱하게 명사를 잘 끊어내는 것과 달리, 만약 합성어가 ab이면 우리는 a와 b 결과만 나오면 되는데 a, ab, b로 쪼개지면서 다시 ab값이 등장해서 문제가 됐다. 그래서 단어 길이가 최대인 값을 지우면 되겠거니 했는데.... abc의 경우 a, ab, abc, b, c로 쪼개져서 abc 뿐만 아니라 ab를 지워야했다. 이를 어떻게 해야할까 하다가 저 코드가 나오게 됐다. 리스트끼리 뺐을 때도 리스트 순서는 바뀌지 않으면서 리스트를 유지하는 법도 배웠다.
또 영어도 한글과 붙어 있으면 값이 다르게 나왔는데, 이게 gpt2가 현재 단어 다음에 나올 단어의 확률을 예측하는 방식으로 학습했기 때문에 ㅠㅠ 붙여쓰는 것과 띄어쓰기를 하는 것은 결과가 달랐다. 원래 이것도 하나하나 코드를 짜려다가 조금 더 사용자에게 자율성을 주자고 조교님이 그러셔서 영어가 포함이 되면 인풋 데이터 그대로 모델에 입력이 됐다.