정말 속전속결이었다. 이렇게 빨리 합격 소식과 함께 출근하게 될 줄은 몰랐다. 이틀만에 서류전형 합격소식이 왔고, 3일 뒤에 면접을 볼 수 있냐는 말에 면접도 기회라서 보게 됐다. 면접을 봤을 때 어느 정도 느낌이 있었지만 면까몰이라고 했으니 기다리고 있었다. 면접 본 다음 날 합격했다고 전화가 와서 바로 준비를 했다.
오랜만에 면접을 봐서 그런지 어떻게 해야할까 질문도 찾아보고, 유튜브도 다시 보게 됐다. 그런데 나 같은 경우는 그럴 필요가 없었다... 이건 뒤에 가서 얘기를 하고 그래도 면접 질문이 궁금해서 찾아오신 분들이 있으니 정리한 걸 공유하려고 한다.
마케팅, 데이터, 기획 쪽 직무?
1. 자기소개
2. 지원동기
3. 펑타이 코리아에 대해서
4. 광고대행사 무슨 일 하는지
5. 지원한 포지션에 뽑혀야 하는 이유 or 강점
6. 성격 장·단점
7. 엑셀, 기본적인 문서 작업 수준
8. 어떤 식으로 스트레스 푸는지
9. 광고대행사의 야근에 대해 어떻게 생각
10. 어떤 동료, 상사와 일하고 싶은지
요즘 내용이 많이 바뀌어서 자소서 관련 부분 팀프로젝트 관련 필히 준비하세요~
*자소서 기반 질문 위주라서 준비해야 한다

열심히 면접왕 이형 1분 자기소개서 보고 연습 했는데, 나는 자기소개도 건너 뛰었다. 그냥 면접관님(팀장님)이 단도직입적으로 자소서에 쓴 내용 때문에 면접 꼭 면접 보고싶었다고... 말하기는 민망하지만 블로그에 쓴 글과도 연관이 되어있다.
그래서 어떤 식으로 그런 결과를 낼 수 있었는지 여쭤보셨다. 그쪽 관련해서는 엄청나게 다양한 시도를 하고, 경험을 직접 해봐서 술술 대답을 할 수 있었다. 반복해서 하는 일인데 괜찮냐는 말과 함께 6개월 동안 하는 직무니까 중간에 그만두지는 않을 거죠?라고 하셔서 '아, 이건 된건가..?' 싶었다. 추가로 경험했던 부분이 퍼포먼스 마케팅을 직접하고 있었다는 식으로 얘기를 해주셨다. 데이터 관련직무인데 인사이트를 가지고 있어서 뽑힌게 아닌가하는 생각이 들었고, 들어가서 어떤걸할지 많이 궁금했다.
엑셀이나 기본적인 문서 다루는 걸 물어보셨으면... 파이썬으로 자동화 해보고싶다고 말씀드리고 싶었는데, 물어보시지는 않았다.

그렇게 일주일만에 모든 절차가 끝나고 합격을 했다. 그리고 지금 출근한지 몇 주가 됐는데.. 현재는 인수인계를 하고 있기도 하고, 일이 5~6월이 몰린다고 해서 할게 많지는 않다. 데이터를 다루고, GA로 데이터를 뽑는 걸 반복해서 한다고 했는데 아직은 제대로 보지는 못 했다.
그런데 예상했던 것과 달리, 펑타이는 수작업이 많아 보인다. 그래서 인턴을 많이 뽑는다는 말이 있을 정도.. 제일기획 자회사다 보니 그만큼 일이 많아서기도 하다. PTKOREA로 회사 상호명이 바뀌었습니다.
회사생활
회사는 자유롭다. 수평적인 가운데 서로 영어 호칭을 쓴다. 복장도 진짜 자유롭다. 처음에 세미 정장느낌으로 입고 갔는데 그럴 필요가 없었다. 블라인드에서는 여름에 반바지도 입을 정도라고.. 간식도 많고, 자율 출퇴근제라서 편하게 다닐 수 있다.
지금 그래서 무슨 일을 하냐고 물으면, 성격상 수작업이나 효율 떨어지는 일을 싫어서 업무 자동화를 시도하고 있다. 진짜 제약이 너무 많기는 하지만 ㅋㅋㅋㅋㅋ 꿋꿋이 하고 있다. 엑셀 MATCH, VLOOKUP 이런 함수를 다 파이썬으로 만들고 있다. 노트북도 좋은게 아닌데 엑셀 함수를 돌리면 거의 하루종일 걸리는 듯 해서 파이썬으로 코드를 짜고 있다(95% 이상 완성). 추가로 크롤링과 자동 캡쳐까지하고 시도하고 있다... 데이터를 어떻게 저장할지, 어떤 규칙으로 분류할지 많은 생각을 하게 된다.
'코테 & 취준' 카테고리의 다른 글
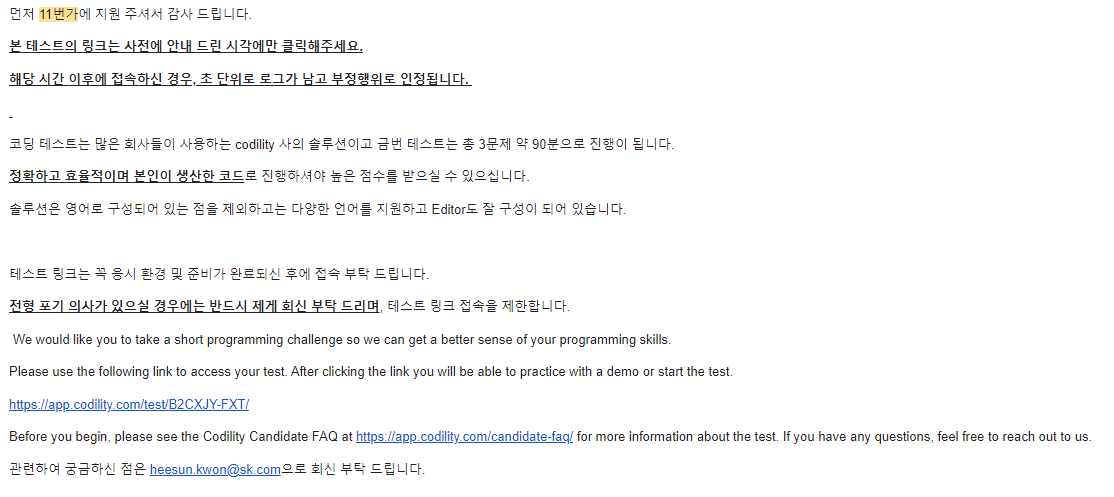
| 11번가 채용 검색 모델링 직무 코딩테스트(코테) 코딜리티 후기 (0) | 2021.12.01 |
|---|---|
| CJ올리브네트웍스 AI Engineer 인성/ 코딩테스트(코테) 후기 (9) | 2021.11.21 |