목차 (작성 예정)
(1) 100% 만족할 파이썬 엑셀 사무 자동화, 회사에서 안 된다면?
(3) 시간 50배 단축, 실무 엑셀 함수 구현 (vlookup, index match 등)
(5) 엑셀 실무용 유용한 함수 및 기능들 파이썬으로 해결
(6) 언제까지 수작업할래? 크롤링과 사진 자동으로 캡쳐, 스샷
회사내 보안이 심하지 않으면 목차 1, 2번은 아마 안 보셨을거라 생각합니다. (운이 좋은 경우) 3편에서는 실무에서 TOP3 안에 드는 엑셀 함수 VLOOKUP 사용법, 유용한 함수들을 파이썬으로 구현하는 방법에 대해서 소개하고자 합니다. 엑셀을 제대로 사용해보지 않은 신입들도 브이룩업?이라고 많이들 들어보셨을텐데 실무에서 엄청 사용하는 것 같습니다.
솔직히 제목 어그로를 어떻게 끌까 하다가, 파이썬 엑셀 사무 자동화라는 타이틀은 빼버리고 필요한 키워드들만 넣었습니다. 단순 조회수를 위해서가 아닌, 저처럼 효율충들을 위한 글입니다. 한 번 사용해보세요 제발...

네이버에서 이런 캐릭터와 함께 오늘은 ~하는 방법 알아볼까요? 하고 특별한 정보도 없이, '그냥 그렇다고 하네요~' 로 끝나는 글들을 혐오해서 유용하지 않으면 욕하셔도 됩니다. 저도 사수 분이 엑셀을 VLOOKUP 사용법과 데이터 전처리하는 방법들을 알려주셨는데, 수작업이 너무 심하고... 데이터가 많다 보니 VLOOKUP이나 다중 조건 함수를 처리하는데 시간이 너무 오래 걸렸습니다. 결국 답답해서 파이썬으로 해결했습니다.
서론이 길었는데 엑셀에서 함수를 처리하는데 멀뚱멀뚱할 동안, 파이썬은 작업을 완료할만큼 속도도 빠르고 시간도 단축된다는 것.
데이터가 적으면 VLOOKUP 함수를 사용하면 얼마 안 걸린다. 하지만 조건이 하나 둘씩 붙어서 다중 조건이 되고, 데이터가 몇 천개 ~ 몇 만개 정도 되면 시간이 기하급수적으로 늘어난다. 다중 조건 INDEX MATCH 조합을 사용했을 때 컴퓨터가 느려서인지 시간이 정말 오래 걸렸다. 하지만 파이썬에서는 다중 조건을 여러번 사용했음에도 몇분도 안 돼서 작업이 완료 됐다.
키워드 : #다중조건, #여러시트, #여러값가져오기


VLOOKUP
이미 아시겠지만 VLOOKUP은 (비교값, 비교대상 범위, 결과를 가져올 열 번호, 옵션)을 활용하지만, 기준값의 우측 데이터만 가져올 수 있다. 하지만 좌측 데이터를 가져오려면 #N/A가 뜨면서 오류가 난다. 다중조건을 사용하기 쉽지 않아서, 많은 분들이 INDEX MATCH를 사용한다. 다른 시트에서 값을 찾으려면 범위 앞에 시트명!을 붙인다. EX) =VLOOKUP($A2, 시트명!$A:$C, 2, FALSE)
INDEX MATCH
INDEX 함수를 사용하여 특정 위치에 해당하는 값을 가져오고, MATCH를 사용해서 기준값이 어디에 위치하는지 정보를 얻을 수 있다. 실무에서 이 두 함수를 조합하는 것으로 보인다. 대부분 옵션은 0이나 FALSE가 들어가는데 정확히 일치한다는 뜻으로 쓰인다.
-INDEX (검색범위, 행번호, 열번호)
-MATCH (찾는 값, 검색범위, 옵션)
-MATCH (1, (첫번째 조건)*(두번째 조건), 옵션)
ㄴ 조건이 충족하면 1(TRUE) 아니면 0(FALSE), 곱해서 1이 되는 조건을 찾는다로 이해하시면 됩니다
*파이썬으로 진행되기 때문에 파이썬(3.7기준), 주피터노트북, pandas 모듈 필수 설치 (csv로 진행)
이걸 어떻게 설명을 할까 생각하다가 직접 보여주는게 좋을거 같아서, 임시로 데이터를 만들었습니다. 오해는 말아주세요. 그리고 파이썬에서 VLOOKUP과 INDEX MATCH 사용법이 비슷해서 INDEX MATCH 기준으로 설명드리겠습니다.

매체별 노출수에 따른 비용을 구하려고 할 때 엑셀 함수로는 =INDEX($J:$J,MATCH(1,($H:$H=$A2)*($I:$I=D2),0),1) 이런 식으로 구하면 별 문제 없이 5000, 7000, 30000, 11000이 입력이 될 것이다. 그렇다면 이것을 어떻게 파이썬으로 구현할까?
1. 파일 불러오기
|
1
2
3
4
|
import pandas as pd # pandas가 없으면 터미널에서 pip install pandas
df = pd.read_csv('위치/파일명.csv', encoding='utf-8-sig') # 직접 불러오기
df = pd.read_clipboard(keep_default_na=False, sep="\t") # 복사해서 불러오기
|
cs |
pandas 모듈을 불러옵니다. 직접 파일의 위치를 찾아서 불러와도 되고, 편하게 원하는 부분만 드래그 후 복사하는 두번째 방법대로 하시면 됩니다. (첫번째 행이 컬럼명이 됩니다 / df는 DataFrame의 약자, 다른 값으로 해도 됩니다)

엑셀 시트를 나눠서 '매체~비용' / '매체명~가격'으로 하셔도 되는데 우선은 시트를 나누지 않고 설명드리겠습니다.
2. 원하는 부분 가져오기
|
1
2
3
4
|
facebook = df['매체'][0]
exposure = df['노출'][0]
facebook, exposure
df[ (df['매체명'] == facebook) & (df['노출수'] == exposure) ]['가격'].values[0]
|
cs |

=INDEX($J:$J,MATCH(1,($H:$H=$A2)*($I:$I=D2),0),1)
매칭을 시키자면, 우리가 필요로하는 A2의 값은 '매체명'컬럼에 0번째 인덱스인 '페이스북'을 facebook/ D2의 값은 '노출수'컬럼에 0번째 인덱스인 '100'을 exposure라고 칭하겠다는 소리입니다.
안쪽에 있는 df들은 MATCH의 조건들이라고 생각하시면 될 것 같고, ['가격']은 $J :$J라고 생각하시면 됩니다. df[( 조건1 ) & ( 조건2 ) ][ $J:$J ]으로 이해하면 편할 듯합니다. MATCH에서 $H:$H=$A2 이 부분은 df['매체명'] == facebook 입니다. H컬럼('매체명')에서 facebook인 애를 찾아줘. $I:$I=D2 이 부분은 df['매체명'] == exposure를 뜻합니다. I컬럼('노출수')에서 exposure를 찾아줘.
그리고 마지막 '.values[0]'은 구한 값을 가져오는 것입니다. (중복값 없이 값이 유일할 때 첫번째 값)
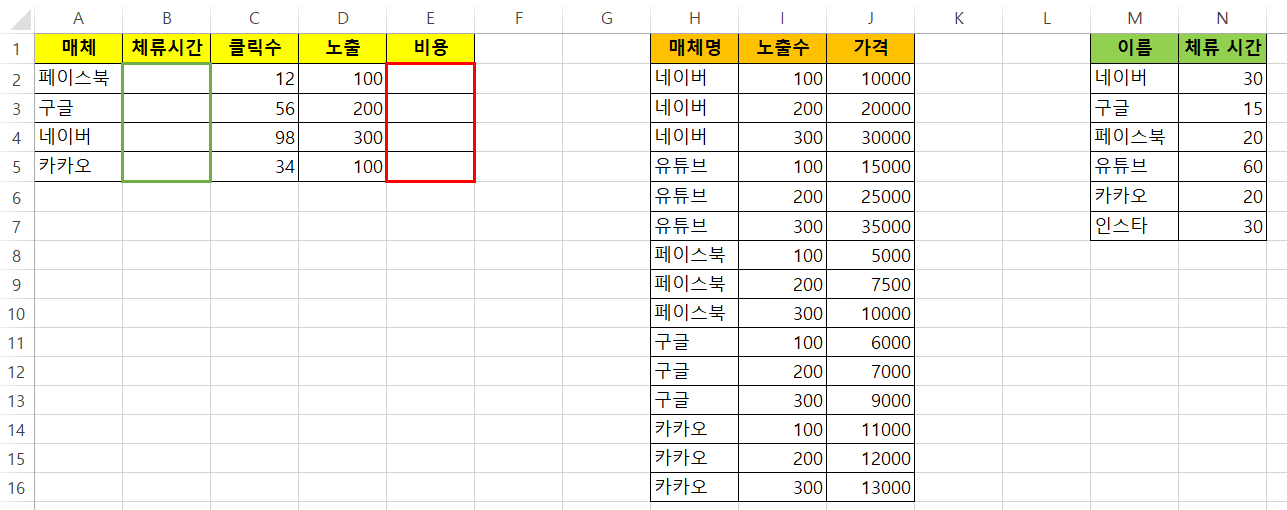
어느정도 이해가 되시나요? 페이스북 체류시간을 구하는 VLOOKUP 함수를 구현한다고 하면 어떻게 하면 될까요?
df[ df['이름'] == facebook ]['체류 시간'] => df [ ] 안에 조건을 하나만 넣으면 됩니다.
3. 값 대입하기
|
1
2
|
facebook_price = df[ (df['매체명'] == facebook) & (df['노출수'] == exposure) ]['가격'].values[0]
df['비용'][0] = facebook_price
|
cs |
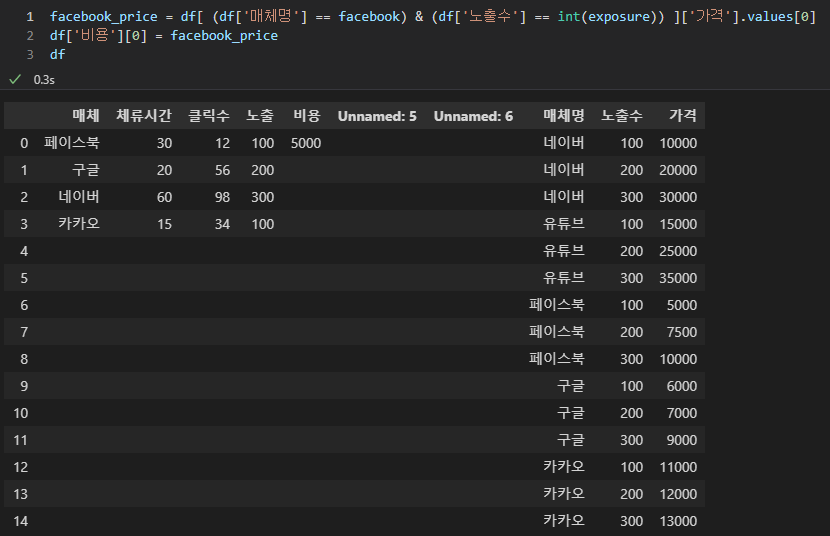
방금 구한 값을 facebook_price라고 칭하고, '비용' 컬럼 0번째 인덱스에 집어넣겠다는 것입니다. 그런데 facebook_price 끝 부분 '.vlaues[0]'은 유의하셔서 보셔야 합니다. 만약에 매체가 페이스북이고 노출 400인 값이 들어왔을 때 비용을 구할 수 없기 때문에 #N/A 값이 생기는 것처럼 파이썬에서도 에러가 납니다.
그렇다면 이 에러를 어떻게 잡을 수 있을까요?
다음 편에 이어서 작성하겠습니다. 원래 여러 내용을 같이 작성하려고 하였으나, 이 게시물을 읽으실 분들은 아직 파이썬이 능숙하지 않으실 것 같아서 우선 위에 내용부터 이해하면 좋겠네요!
정리
VLOOKUP => df [ df['열 이름'] == A2] ['구하고자 하는 값이 있는 열 이름'].values[0]
INDEX/MATCH = > df [ ( df['열 이름1'] == A2 ) & ( df['열 이름2'] == B2 ) ] ['구하고자 하는 값이 있는 열 이름'].values[0]
조건이 추가 되면 df [ (기존 조건) & df['열 이름3'] == C3 ] 안에 &와 함께 조건을 추가하면 됩니다.
다음 글
- 반복해서 값을 적용하는 방법 (이걸 일일이 다 칠 수 없으니...)
- #N/A 값이 나올 때 예외 처리
- 다른 시트에서 값 확인
'할 수 있다. 파이썬' 카테고리의 다른 글
| (5) 효율 100% 엑셀 사무 자동화, 함수 및 기능들 총정리 (파이썬, 판다스) (0) | 2022.01.23 |
|---|---|
| (4) 실무 엑셀 함수 TOP3 자동화 - VLOOKUP 다중조건, INDEX/MATCH 파이썬으로 (0) | 2022.01.22 |
| (2) 파이썬 엑셀 사무 자동화 : 보안 걸린 엑셀 한 번에 뚫기 openpyxl? xlwings? (3) | 2022.01.20 |
| (1) 파이썬 엑셀 사무 자동화 : 회사 사내망 때문에 좌절한 당신... (0) | 2022.01.19 |
| 유튜브 크롤링(3) 올인원 - 채널 제목, 댓글, 조회수, 자막까지 (9) | 2021.09.29 |








