- 첫 프로젝트 글 순서 -
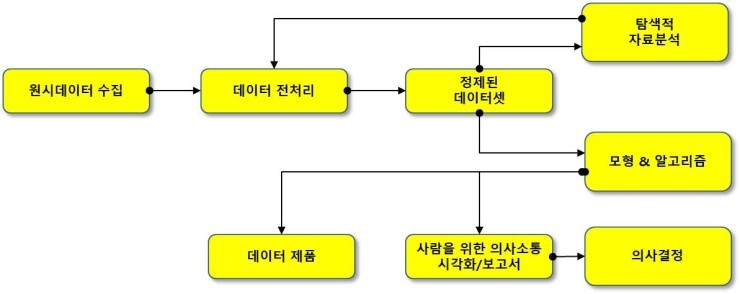
1. 파이썬(python) EDA 데이터분석 주제 정하기
2. 실패한 여기어때 후기 웹스크래핑(web scraping)
4. 판다스(pandas) 데이터 처리 / Matplotlib, Json 시각화
사진 클릭시 사이트로 이동합니다

캐글
Kaggle에서는 데이터 과학 작업에 필요한 모든 코드와 데이터를 찾을 수 있다. 50,000 개 이상의 공개 데이터 세트 와 400,000 개의 공개 노트북을 사용하여 분석이 가능하다고 나온다.
장점 : 고급 데이터가 많다.
단점 : 정의가 약간 불분명하다. 정확한 출처 비공개

서울 열린 데이터 광장
열린데이터광장에서 서울시와 연계 기관이 공개한 공공데이터를 확인할 수 있다.
SHEET (6326) / OpenAPI (5139) / CHART (1320) / FILE (595) / LINK (164)

공공데이터 포털
공공기관이 만들어내는 모든 자료나 정보, 국민 모두의 소통과 협력을 이끌어내는 공적인 정보를 모아놨다.
5만 6천여건의 자료를 확인할 수 있다.
API 자료, 웹 스크래핑 등 다양한 방법을 사용하려고 했으나 처음 프로젝트라서.. 간단하게 엑셀 파일을 사용했다.

제주도 데이터허브
제주도 관련 자료를 찾다가 유용한 자료들이 많아서 여기서 카드 매출 자료를 활용했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
df1= pd.read_csv("jeju_card.csv",engine='python', encoding = 'euc-kr', header=0,
names=['date','city', 'city2', 'type', 'user', 'visitor', 'age', 'sex', 'cost', 'stores'])
df = pd.DataFrame(df1)
|
cs |
만약 한글이 깨지면 encoding에 'utf-8' 또는 'euc-kr'으로 설정을 하면 깨지지 않고 잘 나온다. 함수 사용할때 편리하게 하기 위해서 열을 재정의 했다.
|
1
2
3
4
5
|
df.info()
df.head() df.shape
df.index
df.columns
df['업종명'].unique()
|
cs |
데이터 정제를 위해서 데이터가 어떻게 구성이 됐는지 확인해야 한다. 결측치(NaN값), 중복값 등을 조정해야 한다.
df.replace(to_replace = np.nan, value = ?)
df.fillna(0)
로 데이터를 수정하려고 했으나, 개인 / 단체 / 성별 / 연령이 복잡하게 엉켜있어서 따로 수정하지 않았다. (오차가 크지 않아서 뺌)

컬럼과 타입 확인

데이터 어떻게 보여지는지 확인


97만개의 데이터와 10개의 컬럼

컬럼이 어떤지 확인

컬럼이 어떻게 구성이 됐는지 확인
택시 운송업/버스 운송업이 미분류로 되어 있고, 내항 여객 항공업/정기 항공 항공업 등이 오히려 운송업으로 되어 있어서 데이터를 수정해서 EDA 분석
'도전하자. 프로젝트' 카테고리의 다른 글
| 2-1 파이썬 팀프로젝트 : 네이버 실시간검색 대체 이슈 예측 기획 (0) | 2021.07.16 |
|---|---|
| 1-5. 파이썬 EDA 데이터 분석 팀 프로젝트 간단 정리 (2) | 2021.06.26 |
| 1-4. 파이썬 EDA 데이터 분석 팀 프로젝트 판다스, 시각화 (Matplotlib, Json) (0) | 2021.04.26 |
| 1-2. 파이썬 EDA 데이터분석 팀 프로젝트 웹스크래핑 (Beautifulsoup&Requests) (0) | 2021.04.16 |
| 1-1. 파이썬 EDA 탐색적 데이터분석 프로젝트, 마케팅 관점에서 생각하기 (0) | 2021.04.15 |