- 첫 프로젝트 글 순서 -
1. 파이썬(python) EDA 데이터분석 주제 정하기
2. 실패한 여기어때 후기 웹스크래핑(web scraping)
4. 판다스(pandas) 데이터 처리 / Matplotlib, Json 시각화
웹스크래핑 vs 웹크롤링
웹스크래핑 : 분석을 위해서 특정 데이트를 추출해서 자신이 원하는 형태로 가공한다.
웹크롤링 : 웹사이트의 데이터를 수집하는 모든 작업, 일종의 로봇이라고 생각하면 된다.

파이썬 EDA 데이터분석 프로젝트 과정
목표 : 소비자가 원하는 서비스 파악하기
위치 : 제주도 제주시
업태 : 게스트하우스
수집항목 : 이름, 위치, 가격, 평점, 후기, 기본정보
웹스크레이핑 방법 : 3~5개 숙박 업체 제주도 검색 -> 인기순 -> 100개대략적 위치, 후기 내용 추출 -> 숙소의 위치를 표시하고, 숙박업 어떤 것이 서비스가 필요한지 키워드 10~50위 순위 보여주기 (제외할 키워드 생각)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import requests
from bs4 import BeautifulSoup
import re
data = requests.get('https://www.goodchoice.kr/product/result?sort=ACCURACY&keyword=%EC%A0%9C%EC%A3%BC%EC%8B%9C&type=&sel_date=2021-04-08&sel_date2=2021-04-09&adcno%5B%5D=6&min_price=&max_price=')
name_list =[] #업소명
rate_list=[] #평점
price_list=[] #가격
html = data.text
soup = BeautifulSoup(html, 'html.parser')
n_list = soup.select('div.name strong')
r_list = soup.select('p.score em')
p_list = soup.select('div.map_html b')
for i in n_list:
name = i.string
name_list.append((name).lstrip().replace("\t","").replace("\n","")) #탭이랑 줄바꿈
for i in r_list:
rate = i.string
rate_list.append(rate)
for i in p_list:
price = i.string
price_list.append(price)
#print(rank_list)
#print(music_title)
#print(music_artist)
for i in range(len(name_list)) :
print('업소명:' , name_list[i])
print('평점:' , rate_list[i])
print('가격:' , price_list[i])
print('-------------------------------')
|
cs |
여기어때 사이트에 들어갔는데 데이터가 너무 방대해서, 제주시와 게스트하우스로 한정을 지었다. 우선 후기가 따로 들어가 있어서 일단 업소명, 평점, 가격을 추출하고 그 다음에 후기를 하나씩 추출하는 방식으로 진행을 하려고 했다.
BeautifulSoup : HTML과 XML 파일로부터 데이터를 가져오기 위한 라이브러리
find : html tag를 통한 크롤링
select : css를 통한 크롤링
find, select_one : 첫 번째 태그를 찾음
find_all, select : 모든 태그를 찾음
find보다 select가 '>'로 하위 태그로 접근이 쉬워서 여기어때 사이트에서 F12를 누르고 Ctrl + Shift + C 를 눌러서 element를 찾아서 업소명, 평점, 가격 별로 추출을 했다.

제목 스크래핑하기 제목을 커서위에 대보니까, div class name > strong에 포함되어 있는 것을 확인할 수 있다. 하지만 출력을 해보면 줄바꿈과 탭으로 인해서 깔끔해보이지 않아서 replace()를 한 것이다. 중간중간 어떻게 출력이 되는지 print(n_list)를 각각 해보는 것을 추천한다.


결과를 확인해보니까 잘 출력되고 있다. 일정 부분까지 가고 스크롤이 내려가지 않아서 마지막에 에러가 뜨는 것으로 보인다.
한계 1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from time import sleep
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys #텍스트 외에 특수 키를 입력하기 위한 모듈
driver = webdriver.Chrome('chromedriver.exe')
url = "https://www.goodchoice.kr/"
driver.implicitly_wait(5)
driver.get(url)
search = driver.find_element_by_xpath('/html/body/div[1]/header/section/button[2]')
search.click()
#search.clear()
search = driver.find_element_by_xpath('//*[@id="keyword"]')
driver.implicitly_wait(5)
search.send_keys("제주시")
search.send_keys(Keys.ENTER)
#driver.implicitly_wait(5)
driver.set_window_size(1400,1000)
search = driver.find_element_by_xpath('//*[@id="content"]/div[1]/section[2]/ul/li[6]/label')
search.click()
search = driver.find_element_by_xpath('//*[@id="content"]/div[1]/div[2]/button[2]')
search.click()
|
cs |
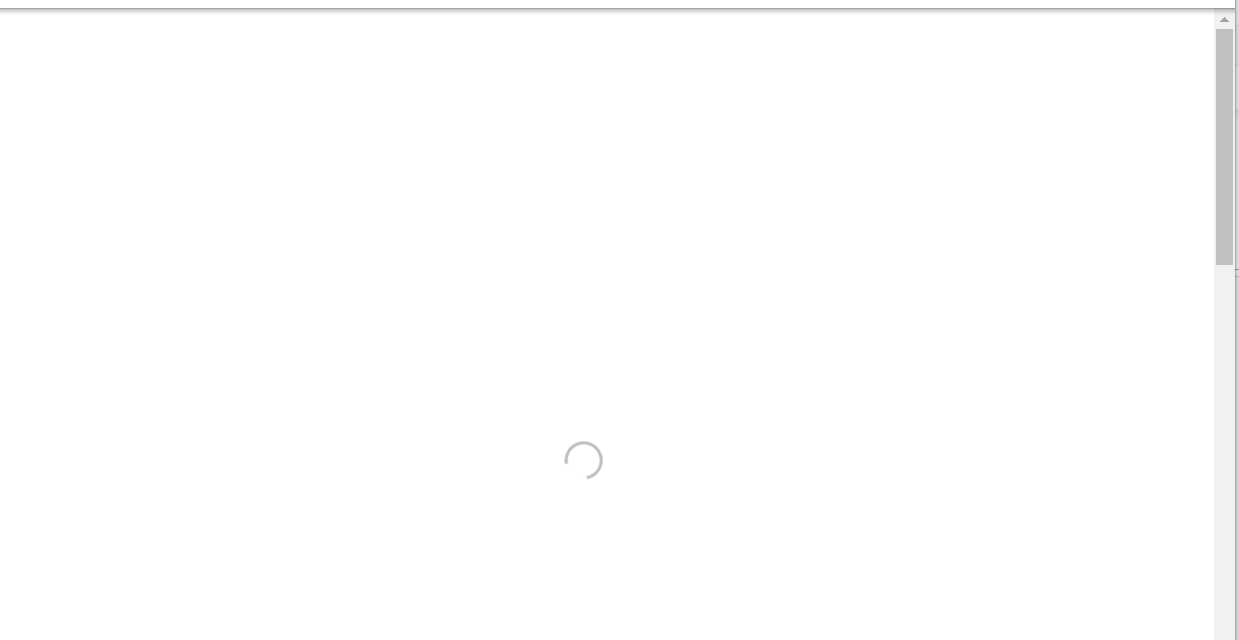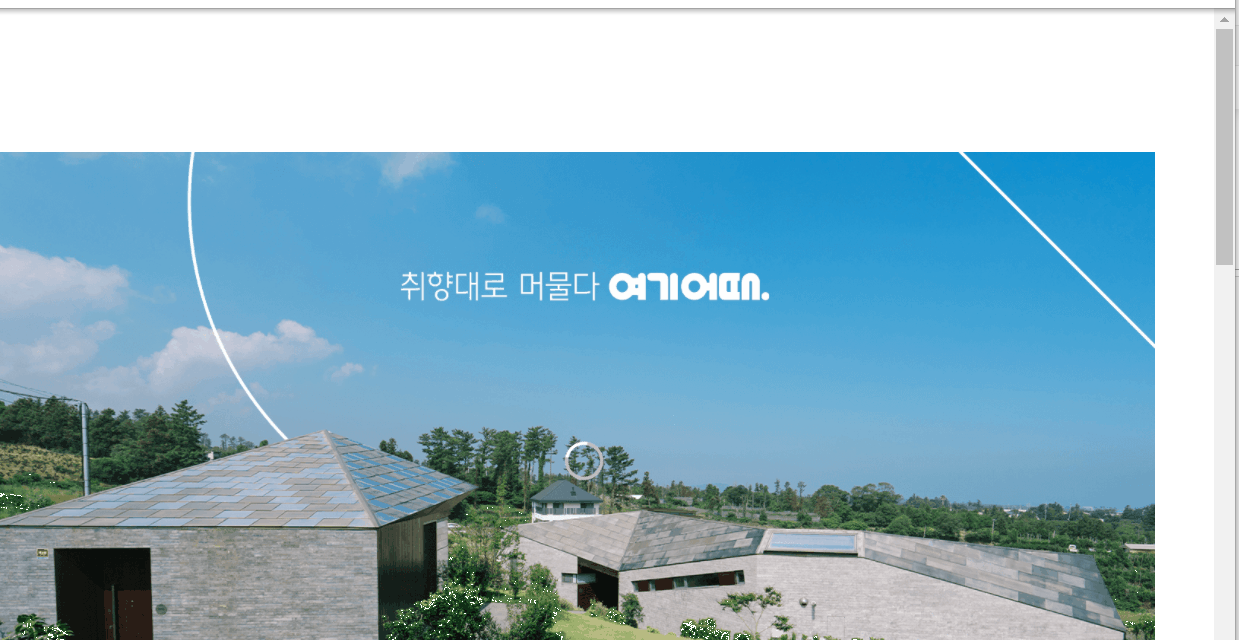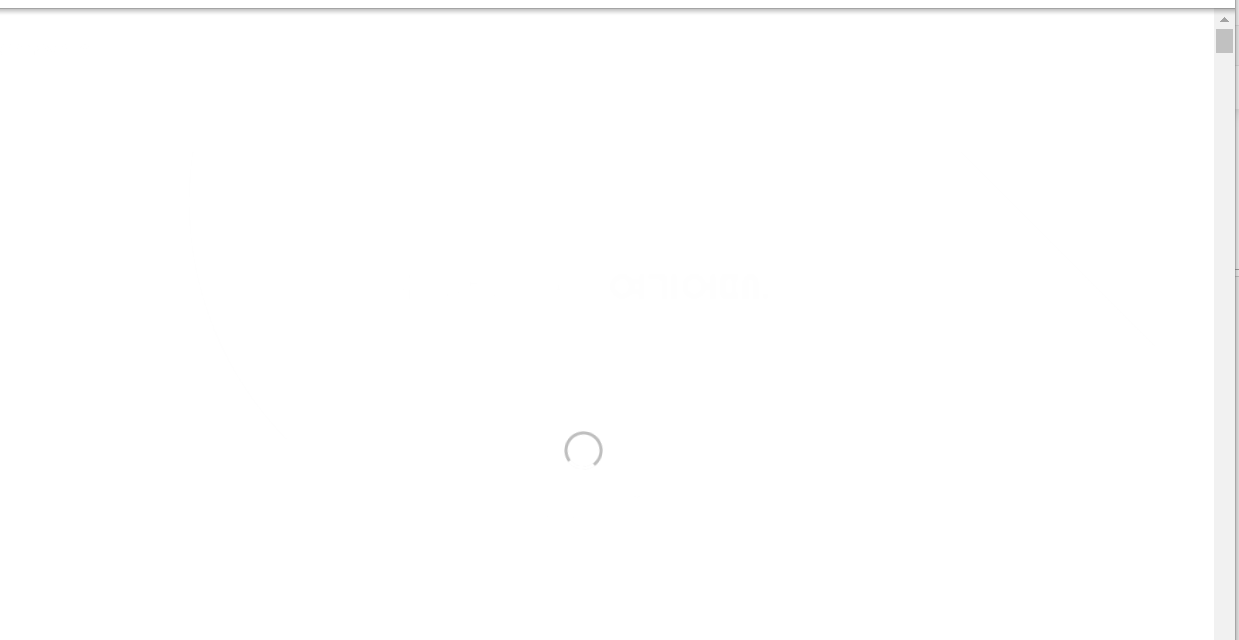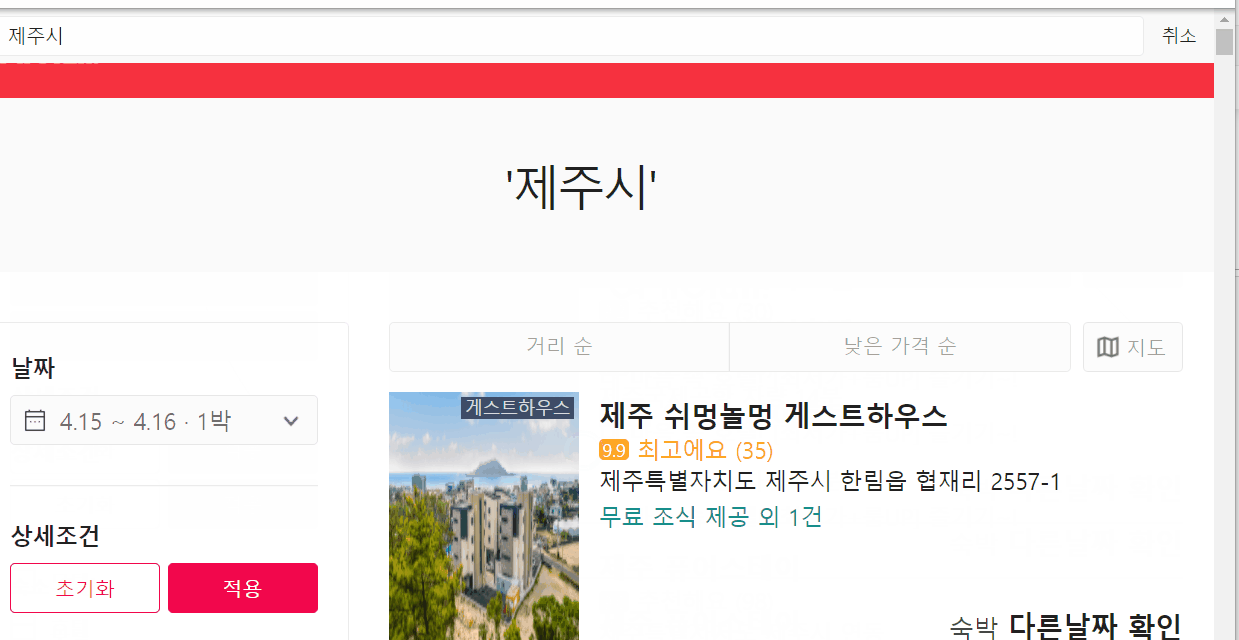
여기어때 싸이트에 들어감 -> 검색 창을 한 번 누르고, 한 번 더 눌러야함을 알 수 있음 -> 제주시를 입력하고, 엔터를 눌러서 검색 -> (gif에는 안 나오지만) 밑에 게스트하우스 클릭박스를 선택 후, 적용 클릭
우선 여기까지 구현을 하고 나서 게스트하우스를 하나씩 클릭하고 돌아오고는 할 수 있는데, 배운 선에서 웹 스크래핑으로 열린 창에 새로운 url 주소를 얻는 방법을 몰라서 벽에 부딪혔다 ㅠㅠㅠ
이건 나중에 개발자 친구한테 알아내서 추가하겠습니다.
한계 2
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
from wordcloud import WordCloud
from konlpy.tag import Twitter
from collections import Counter
# open으로 txt파일을 열고 read()를 이용하여 읽는다.
text = open('news.txt', encoding='utf-8').read()
twitter = Twitter()
# twitter함수를 통해 읽어들인 내용의 형태소를 분석한다.
sentences_tag = []
sentences_tag = twitter.pos(text)
noun_adj_list = []
# tag가 명사이거나 형용사인 단어들만 noun_adj_list에 넣어준다.
for word, tag in sentences_tag:
if tag in ['Noun' , 'Adjective']:
noun_adj_list.append(word)
# 가장 많이 나온 단어부터 40개를 저장한다.
counts = Counter(noun_adj_list)
tags = counts.most_common(40)
# WordCloud를 생성한다.
# 한글을 분석하기위해 font를 한글로 지정해주어야 된다. macOS는 .otf , window는 .ttf 파일의 위치를
# 지정해준다. (ex. '/Font/GodoM.otf')
wc = WordCloud(font_path='c:\Window\Fonts\malgun.ttf' ,background_color="white", max_font_size=60)
cloud = wc.generate_from_frequencies(dict(tags))
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 8))
plt.axis('off')
plt.imshow(cloud)
# plt.to_file('test.jpg') test.jpg 파일로 저장
plt.show()
|
cs |

수업시간에 잠깐 배웠던 내용을 가지고 후기에 어떤 키워드가 많이 사용되는지 확인하려고 했다. wordcloud를 생성해서 후기를 모으고 상위 단어 top50 개를 추리려고 했다. 하지만 웹 스크래핑도 안 될뿐만 아니라, 예외 단어들을 어떻게 정할지 하나하나 생각해야 했다. 사람들이 쓰는 방법들이 다 달라서 좋다, 좋았어요, 좋구만, 좋아요 다 다르게 인식하면 어쩌나하고 강사님과 상의 후에 다른 방식으로 진행하기로 했다.
'도전하자. 프로젝트' 카테고리의 다른 글
| 2-1 파이썬 팀프로젝트 : 네이버 실시간검색 대체 이슈 예측 기획 (0) | 2021.07.16 |
|---|---|
| 1-5. 파이썬 EDA 데이터 분석 팀 프로젝트 간단 정리 (2) | 2021.06.26 |
| 1-4. 파이썬 EDA 데이터 분석 팀 프로젝트 판다스, 시각화 (Matplotlib, Json) (0) | 2021.04.26 |
| 1-3. 파이썬 EDA 데이터분석 팀 프로젝트 데이터 수집, 정제 등 (0) | 2021.04.26 |
| 1-1. 파이썬 EDA 탐색적 데이터분석 프로젝트, 마케팅 관점에서 생각하기 (0) | 2021.04.15 |