336x280(권장), 300x250(권장), 250x250, 200x200 크기의 광고 코드만 넣을 수 있습니다.
- 첫 프로젝트 글 순서 -
1. 파이썬(python) EDA 데이터분석 주제 정하기
2. 실패한 여기어때 후기 웹스크래핑(web scraping)
4. 판다스(pandas) 데이터 처리 / Matplotlib, Json 시각화
데이터를 어떤 식으로 그룹핑을 할지 고민을 하다가 cost(비용)으로 하기로 했다.
-큰 틀에서 묶기-
제주시/서귀포시 매출 비교
업종별 매출
성별/연령별 소비
개별/단체 소비
성수기/비수기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
# 월별 / 남성 / 나이/ 종류 별 금액
sum_stores = df.groupby(['date','sex','age','stores'])['cost'].sum()
print(sum_stores.plot(kind='bar', rot=90) )
#성수기 비수기
sum_sb = df.groupby('date')['cost'].sum()
#업종별 매출
sum_stores = df.groupby('stores')['cost'].sum()
#성별, 연령별 소비 순위
sum_sa = df.groupby(['sex','age'])['cost'].sum()
sum_sa
#성별 업종 이용현황, 연령별 업종 이용현황, 성별&연령별 업종 이용현황
sum_st = df.groupby(['sex','stores'])['cost'].sum()
sum_at = df.groupby(['age','stores'])['cost'].sum()
sum_sat = df.groupby(['sex','age','stores'])['cost'].sum()
#제주시 서귀포시 소비 비교 / 읍면동별 소비 비교
sum_city = df.groupby(['city'])['cost'].sum()
sum_city2 = df.groupby(['city2'])['cost'].sum()
#제주시 서귀포시 업종별 소비 비교 / 읍면동 업종별 소비 비교
sum_ct = df.groupby(['city','stores'])['cost'].sum()
sum_ct2 = df.groupby(['city2','stores'])['cost'].sum()
#지역 각 성별 업종 이용률
sum_cst2 = df.groupby(['city2','sex','stores'])['cost'].sum()
#개별과 단체 총금액 비교
sum_visitor = df.groupby(['visitor'])['cost'].sum()
#개별 단체 성별 총금액 비교 / 개별 단체 업종별 총금액 비교 / 단체 or 개별에서 이용자별 금액비교
sum_vs = df.groupby(['visitor, sex'])['cost'].sum()
sum_vt = df.groupby(['visitor, stores'])['cost'].sum()
sum_vu = df.groupby(['visitor, user'])['cost'].sum()
#개별(내국인, 법인, 외국인) / 단체에서 이용하는 업종
sum_vut = df.groupby(['visitor, user, stores'])['cost'].sum()
|
cs |
우선 데이터가 어떻게 보여지는지 기본적인 시각화를 진행했다. 만약 세부정보가 필요하면, 세분화해서 EDA데이터 분석하는데 유용하게 활용했다.
|
1
2
3
4
5
6
|
#특정 업종, 날짜
sum_sdt = df[(df.stores == '소매업') & (df.date == 'Feb-17')].groupby('type')['cost'].sum()
#특정 연령,
sum_ast = df[df.age==10].groupby(['sex','type'])['cost'].sum().sort_values().tail(20)
|
cs |
열에서 특정 연령, 성별, 업종만 뽑아내서 더하고 싶으면, df[df.열 == '열 속성'].groupby를 이용해주면 된다. 특정 열에서 속성을 추출해서 더하는 코드가 나오지 않아서 참고하면 좋을 것 같다.
|
1
2
3
4
5
|
plt.rc('font',family='Malgun Gothic')
plt.figure(figsize=[20,10])
plt.style.use('ggplot')
sum_sa = df.groupby(['sex','age'])['cost'].sum()
sum_sa.plot(kind='bar')
|
cs |
matplotlib 함수를 활용하여 가장 기본적인 시각화를 했다.
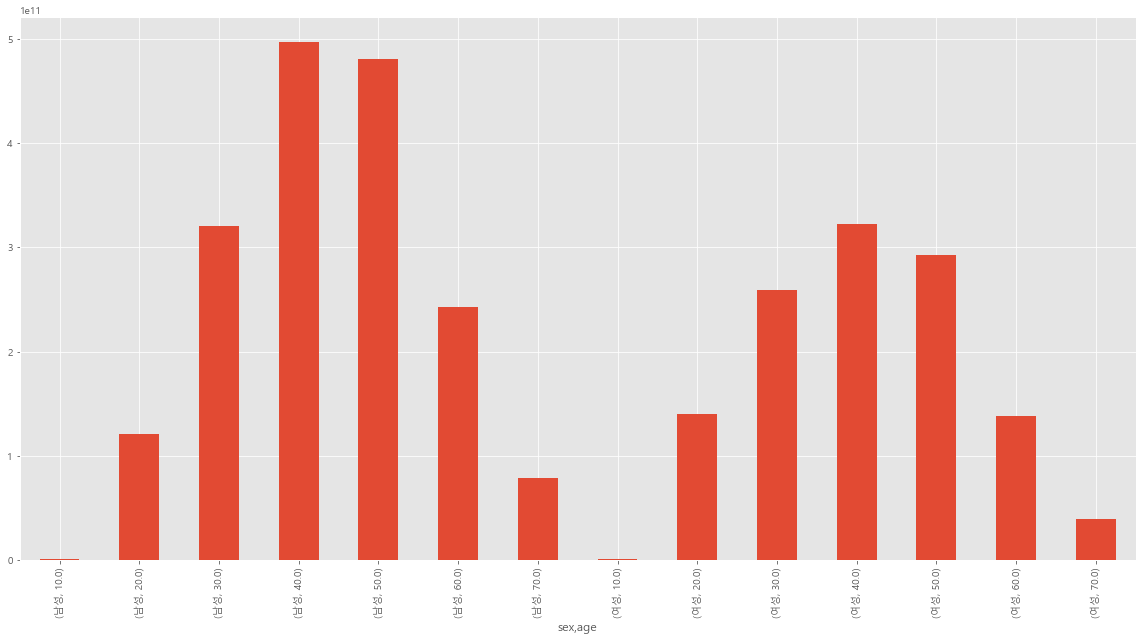

얘네를 모아서 EDA 데이터 분석에 필요한 자료만 모으고, title, x축, y축, 그래프 색, 그래프 종류(box, bar, barh, violinplot, pie) 등으로 다시 시각화 과정을 진행했다.
|
1
2
3
4
5
6
7
8
9
10
|
plt.figure(figsize=[10,5])
title_font = {'fontsize': 16, 'fontweight': 'bold'}
plt.title('도민 소매업 매출 순위', fontdict = title_font, loc = 'center', pad =20)
sum = df[(df.stores=='소매업') & (df.visitor=='도민')].groupby('type')['cost'].sum()
ax = plt.subplot()
ax.set_xticklabels(['0','500억', '1000억', '1500억', '2000억', '2500억', '800억'])
sum.plot(kind = 'barh', color = '#f39189')
plt.xlabel('Total Amount')
plt.ylabel('Type of Business')
sum_sa
|
cs |

barh 막대 그래프
|
1
2
3
4
5
6
|
explode = [ 0.1, 0.1,0.1, 0.1,0.1,0,0 ]
title_font = {'fontsize': 16, 'fontweight': 'bold'}
plt.title('업종별 매출', fontdict=title_font, loc='center', pad= 20)
sum_sa = df.groupby('stores')['cost'].sum().sort_values()
sum_sa.plot(kind='pie',y='sum', autopct = '%1.1f%%',explode=explode, startangle=0)
|
cs |
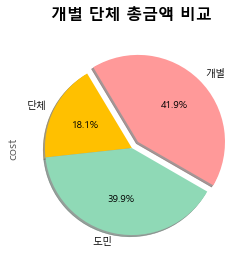
pie 그래프
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import folium
from folium import plugins
from folium.plugins import MarkerCluster
import json
df1= pd.read_csv("jeju_card.csv",engine='python', encoding = 'euc-kr', header=0,
names=['date','city', 'city2', 'type', 'user', 'visitor', 'age', 'sex', 'cost', 'stores'])
# 카드 이용금액 csv
df2 = pd.read_csv("jeju_lalo.csv",engine='python', encoding = 'euc-kr')
#df2 = 제주도의 행정구역을 위도 및 경도로 나눈 csv
df3 = pd.read_csv("jeju_cost.csv",engine='python', encoding = 'euc-kr')
#df3 = 구역별 소비를 나타낸 csv
df = pd.DataFrame(df1)
lat = df2['위도'].mean()
long = df2['경도'].mean()
m = folium.Map([lat,long], zoom_start=9)
# lay, long의 평균값으로 지도의 첫 화면 지정 / 줌lv = 9
a = df.groupby(['city2'], as_index = False)['cost'].sum()
# city2 컬럼을 그룹바이하고 그 중의 cost컬럼을 모두 sum.
# as_index = False : 그룹 바이 한 데이터 프레임에 index 번호를 추가해준다.
#---------------------------제이슨 표시---------------------------
#제주도의 행정구역을 시각화로 나눠주는 geojson road
with open("Jeju_json3.geojson", mode='rt',encoding='utf-8') as f:
jeju_json = json.loads(f.read())
f.close()
folium.GeoJson(jeju_json, name='jeju_haejoeng').add_to(m)
#------------------------------------------------------------------
#---------------------------제이슨 조건---------------------------
folium.Choropleth(geo_data = jeju_json, # geo_data load
data = df3, # 위치를 표현해줄 데이터 load
columns = ('읍면동', '이용금액'), # ('지도에 표현할 컬럼', '비교할 컬럼')
key_on = 'feature.properties.adm_nm', # geo_data load 후 데이터를 어디서 받을지
fill_color = 'YlGn', # 비교해서 나타낼 색 / 노란색/초록색
fill_opacity = 0.8, #
line_opacity = 0.5, #
legend_name = '지역별 매출액' # 우측 상단에 나오는 bar 이름
).add_to(m)
#------------------------------------------------------------------
marker_cluster = MarkerCluster().add_to(m) # 마커 클러스터 추가 (현재 코드엔 사용 안함.)
for i in range(len(a.index)):
b = df2[df2['읍면동'] == a.iloc[i,0]] # df2 읍면동 컬럼에서 a의 [i,0] 값과 같은것을 추출
sub_lat = b.iloc[0,4] #
sub_long = b.iloc[0,5] # 위, 경도 설정
title = b.iloc[0,2] # title 설정
folium.Marker([sub_lat,sub_long],tooltip = title).add_to(m)
# 마커 설정 마커클러스터를 실행시키려면 add_to(marker_cluster)
#folium.LayerControl(collapsed=False).add_to(m) # 그룹화된 기능들을 사용하기위해 컨트롤러 설정
m.save('jeju.folium.html')
|
cs |

제주도 marker
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import folium
from folium import plugins
from folium.plugins import MarkerCluster
import json
# json 도시별 행정구역 구분 sggnm
df1= pd.read_csv(r"C:\Users\rhdud\Desktop\py_team\read_file\123123.csv",engine='python', encoding = 'euc-kr', header=0,
names=['date','city', 'city2', 'type', 'user', 'visitor', 'age', 'sex', 'cost', 'stores'])
df2 = pd.read_csv(r"C:\Users\rhdud\Desktop\py_team\read_file\jeju_lalo.csv",engine='python', encoding = 'euc-kr')
#df2 = 제주도 행정구역 위도 및 경도로 나눈 csv
df3 = pd.read_csv(r"C:\Users\rhdud\Desktop\py_team\read_file\jeju_cost.csv",engine='python', encoding = 'euc-kr')
df = pd.DataFrame(df1)
lat = df2['위도'].mean()
long = df2['경도'].mean()
m = folium.Map([lat,long],zoom_start=9)
# lay, long의 평균값으로 지도의 첫 화면 지정 / 줌lv = 9
a = df.groupby(['city2','sex','stores'], as_index = False)['cost'].sum()
'''
#---------------------------폴리움 그룹화---------------------------
fg = folium.FeatureGroup(name = '도시별 표현')
m.add_child(fg)
g1 = plugins.FeatureGroupSubGroup(fg, '제주시')
m.add_child(g1)
g2 = plugins.FeatureGroupSubGroup(fg, '서귀포시')
m.add_child(g2)
g3 = plugins.FeatureGroupSubGroup(fg, 'Json으로 표현')
m.add_child(g3)
#------------------------------------------------------------------
'''
#---------------------------제이슨 표시---------------------------
with open(r"C:\Users\rhdud\Desktop\py_team\read_file\Jeju_json.geojson", mode='rt',encoding='utf-8') as f:
jeju_json = json.loads(f.read())
f.close()
folium.GeoJson(jeju_json, name='jeju_haejoeng').add_to(m)
#------------------------------------------------------------------
#---------------------------제이슨 조건---------------------------
key_by = 'feature.properties.adm_nm'
folium.Choropleth(geo_data = jeju_json,
data = df3,
columns = ['읍면동', '이용금액'],
key_on = key_by[key_by.rfind(' ')+1 :],
fill_color='YlGn',
fill_opacity=0.8
).add_to(m)
#------------------------------------------------------------------
m.save('jeju_data1.html')
|
cs |

제주도 choropleth
'도전하자. 프로젝트' 카테고리의 다른 글
| 2-1 파이썬 팀프로젝트 : 네이버 실시간검색 대체 이슈 예측 기획 (0) | 2021.07.16 |
|---|---|
| 1-5. 파이썬 EDA 데이터 분석 팀 프로젝트 간단 정리 (2) | 2021.06.26 |
| 1-3. 파이썬 EDA 데이터분석 팀 프로젝트 데이터 수집, 정제 등 (0) | 2021.04.26 |
| 1-2. 파이썬 EDA 데이터분석 팀 프로젝트 웹스크래핑 (Beautifulsoup&Requests) (0) | 2021.04.16 |
| 1-1. 파이썬 EDA 탐색적 데이터분석 프로젝트, 마케팅 관점에서 생각하기 (0) | 2021.04.15 |