- 첫 프로젝트 글 순서 -
1. 파이썬(python) EDA 데이터분석 주제 정하기
2. 실패한 여기어때 후기 웹스크래핑(web scraping)
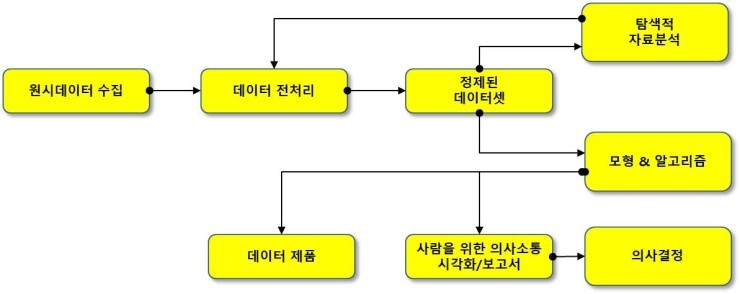
3. 데이터 수집 방법 & 데이터 추출, 정제
4. 판다스(pandas) 데이터 처리 / Matplotlib, Json 시각화
5. 정리

지난 번에 글을 올린지 딱 2달이 지났다. 이후에 프로젝트를 벌써 3개를 더했는데... 틈만 나면 해야지 해야지 하는데 시간이 많이 나지를 않았다. 머신러닝, 인공지능 등 개념학습 따라가기도 너무 벅찼고, 모델은 아직까지 이해도 안 되는 수준이긴 하지만 더 늦어지면 안 될 것 같아서 미리미리 간단하게 쓰기로 했다.
솔직히 EDA 데이터 분석 팀프로젝트 5번째 항목 정리를 왜 했지라는 생각이 든다. 그래서 간단하게 어떻게 진행을 했고 어떤 것을 사용했는지, 결론은 어떻게 도출했는지만 간단하게 쓰려고 한다. 부지런하게 남은 프로젝트들도 업로드하면서 github도 사용해봐야 하는데 쉽지 않다. 개인적으로 마케팅 분석하고 sns까지 하다보니 시간이 남지 않는다. 해커톤까지 ???

나중에 알게 된건데 필수로 써야하는 부분이 몇개 있다.
1. 언어(파이썬, 자바, C 등..), 패키지(matplolib, pandas 등), 툴(주피터노트북, 코랩, 파이참 등..)
2. 일정표
3. 과정, 순서 등
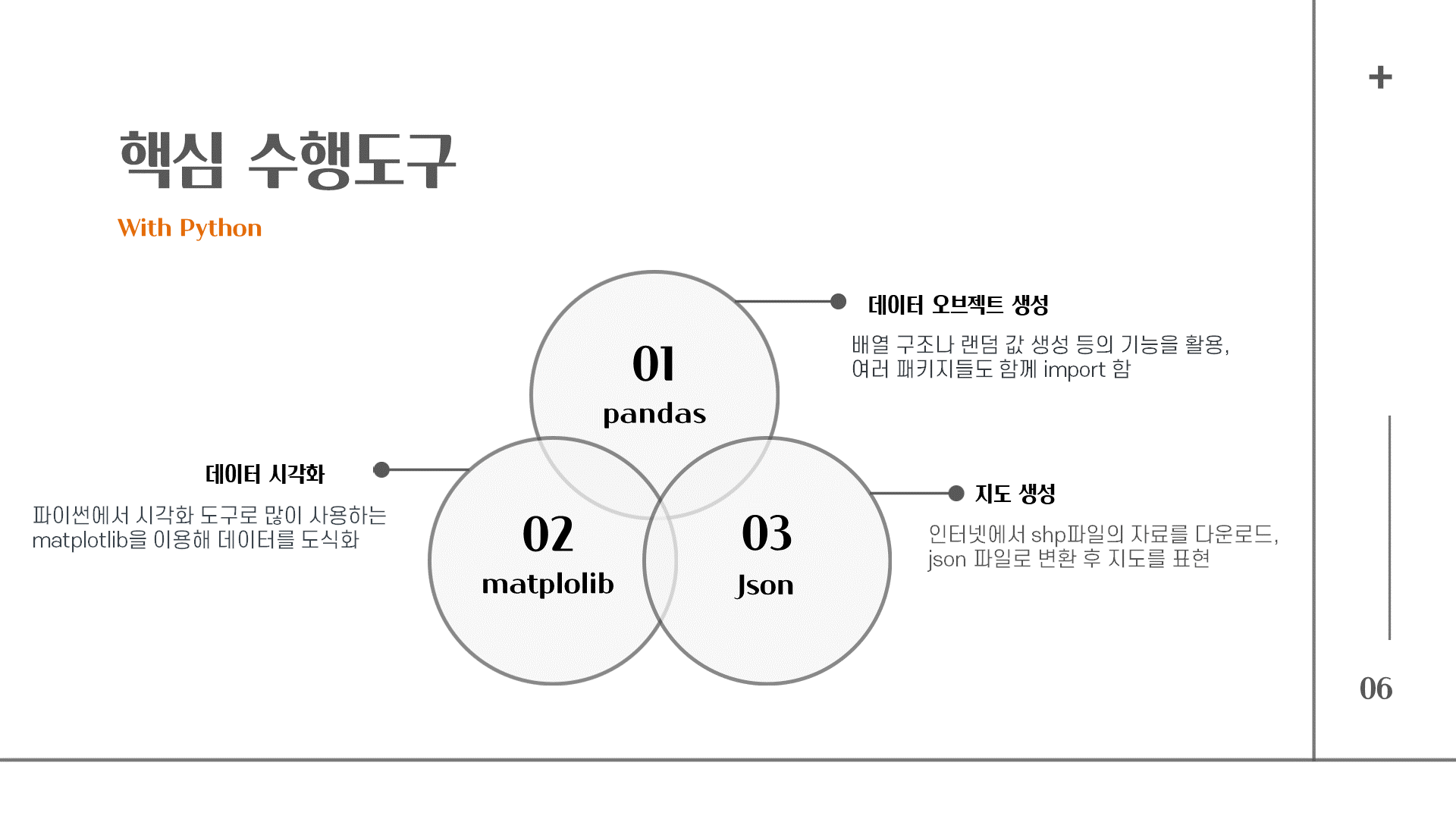
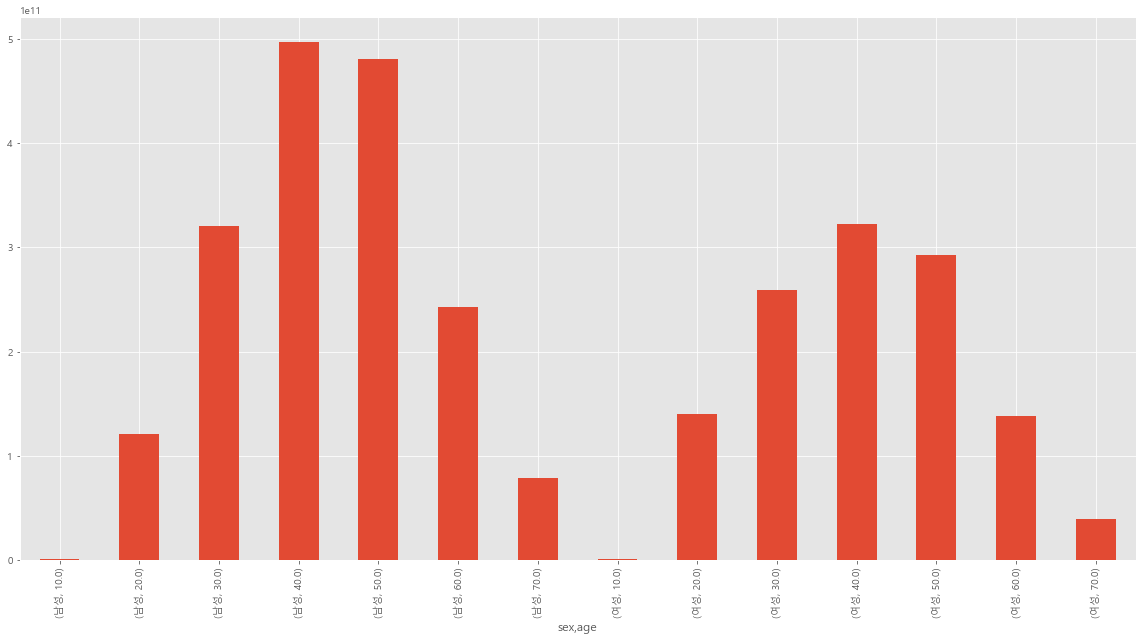
이번에 주로 사용했던 것은 pandas, matplolib, json을 사용하였다. sns도 사용하려고 했는데 당시에는 생각보다 쉽지 않아서 matplotlib으로 데이터 시각화를 대부분 담당했다. 나중에도 시각화하는데 많이 사용하기 때문에 알아두는 것이 좋다.
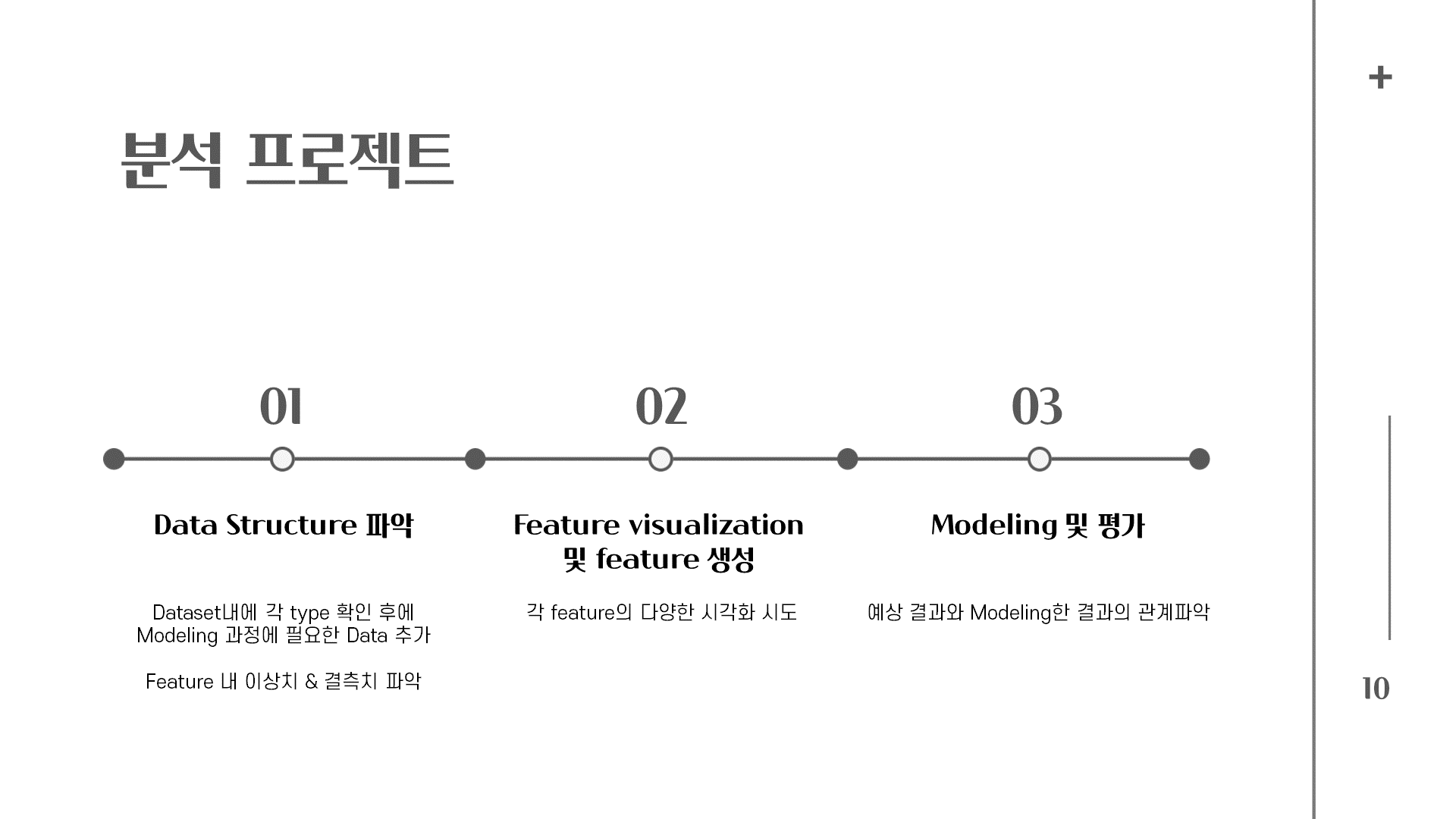
과정, 순서 등은 어떤 부분에서 얼만큼의 시간을 썼는지 쓰면 좋을 것이다.

프로젝트를 할 때 주제가 많이 제한적이게 된 이유는 데이터를 구하기 너무 어렵다. 예전에 데이터가 곧 권력이고 힘이라고 했던 부분, 그리고 스프링쿨러? 온도, 습도 등의 데이터를 모아놨던 회사가 구글에 데이터를 고가에 팔았다는 것, 머신러닝을 하면서 더 느끼게 됐다.

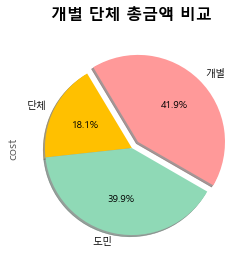
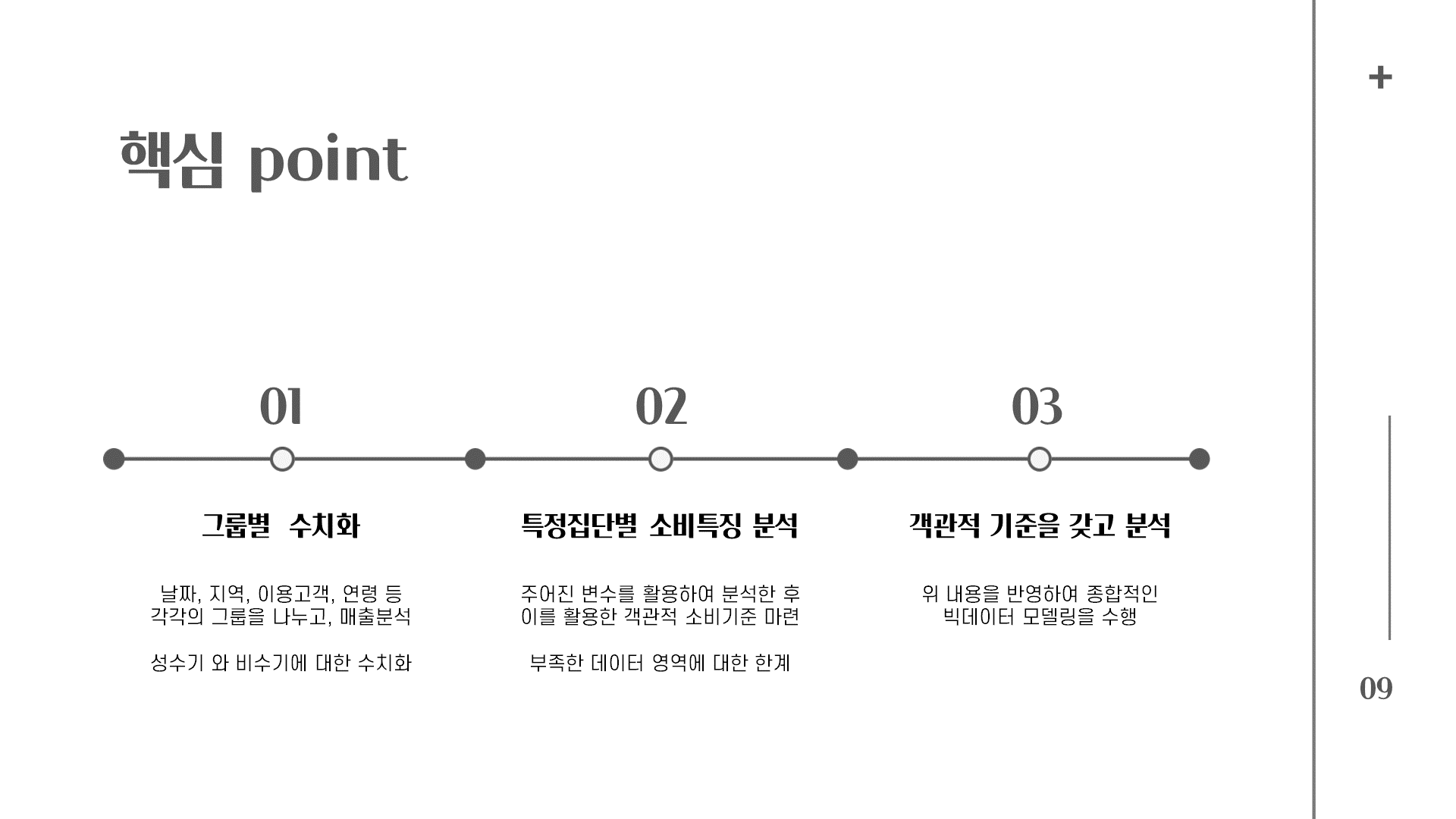
데이터를 토대로 결론 도출을 해봤다
- 창업시 고려해야할 위치와 업종을 데이터를 통해 파악하기 쉽다.
- 업종에서는 소매업이 가장 많고, 그 다음이 음식점, 그리고 도민의 소매업이 평상시에도 많다.
- 성수기 때 슈퍼마켓, 체인화 편의점 이용률이 많이 늘어났다. 숙박업을 할 경우 미리 물품 구매를 하면 더 좋을 것이다.
=> 하고 싶은 업종을 입력했을 때, 위치, 경쟁, 타겟층을 보여주는 프로그램을 보여줘도 나쁘지 않을 것 같다.
'도전하자. 프로젝트' 카테고리의 다른 글
| 2-2 파이썬 프로젝트 : BS4 웹크롤링, 형태소 분석, (0) | 2021.07.17 |
|---|---|
| 2-1 파이썬 팀프로젝트 : 네이버 실시간검색 대체 이슈 예측 기획 (0) | 2021.07.16 |
| 1-4. 파이썬 EDA 데이터 분석 팀 프로젝트 판다스, 시각화 (Matplotlib, Json) (0) | 2021.04.26 |
| 1-3. 파이썬 EDA 데이터분석 팀 프로젝트 데이터 수집, 정제 등 (0) | 2021.04.26 |
| 1-2. 파이썬 EDA 데이터분석 팀 프로젝트 웹스크래핑 (Beautifulsoup&Requests) (0) | 2021.04.16 |