목차 (작성 예정)
(1) 100% 만족할 파이썬 엑셀 사무 자동화, 회사에서 안 된다면?
(3) 시간 50배 단축, 실무 엑셀 함수 구현 (vlookup, index match 등)
(5) 엑셀 실무용 유용한 함수 및 기능들 파이썬으로 해결
(6) 언제까지 수작업할래? 크롤링과 사진 자동으로 캡쳐, 스샷
오랜만에 글을 썼는데.. 사무자동화 마지막 글이네요. 우선 생각했던건 여기까지고 추가로 필요한 부분 있으면 제가 또 만들지 않을까.. bs4나 셀레니움(selenium)으로 크롤링까지는 금방 완성이 되는데, 자동 캡쳐나 스크린샷을 찍는 방법은 처음으로 시도했다. 검색을 해보면 전체화면 캡쳐를 하는게 대부분이고, 내가 원하는 element나 특정 부분 캡쳐는 설명이 별로 없었다.
복잡하게 좌표값이나 height, witdh를 다 구해서 전체화면 스크린샷을 찍고 원하는 부분만 가져오는 것도 많았다. 물론 크롬에서 쉽게 특정 element를 캡쳐하는 방법도 있었다. 약간 신세계를 경험하는 것 같았는데 자동화가 아니다 보니 패스.. 그래도 짧게 소개해보자면
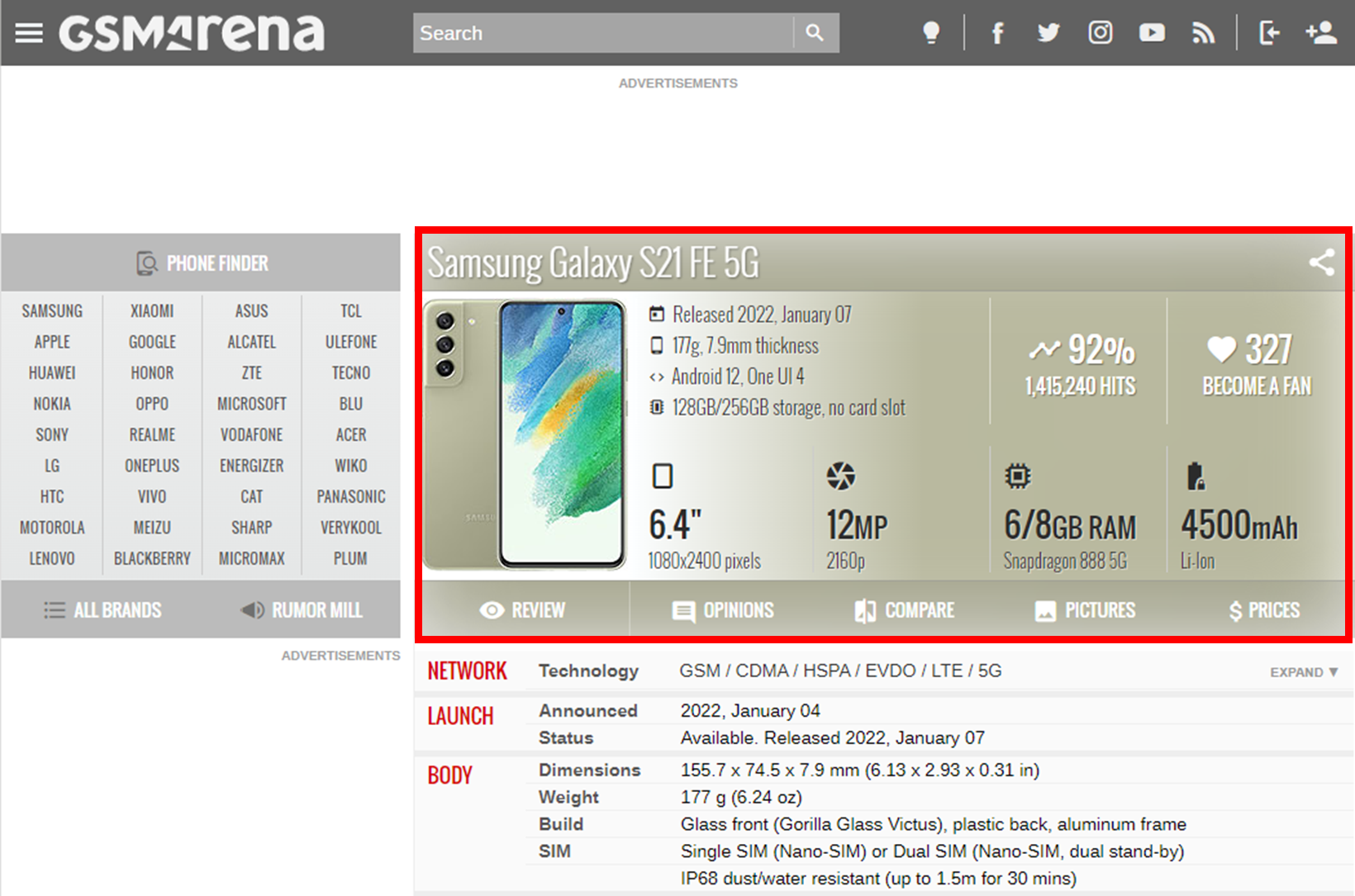

GSMARENA라는 싸이트에서 빨간색 박스를 친 부분의 사진만 가져오고 싶을 때, 우선 F12 개발자 도구를 켠다. 그 다음에 Elements에서 저 부분을 포함하는 class나 id를 찾고 클릭을 한다. 이후에 shift + crtl + p 를 누른다.


그러면 개발자용 명령창이 뜨게 되는데 약자로 cnod를 검색. capture node screenshot이 나오게 되는데, 클릭하면 바로 캡쳐가 된다. 심지어 결과도 깔끔하고 화질도 나쁘지 않다. 그러면 뭐하나.. 자동이 아니면 매번 이 작업을 반복해야 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
element = driver.find_element_by_id('specs-list')
element.screenshot('screenshot.png')
element_png = element.screenshot_as_png
with open('screenshot.png', "wb") as file:
file.write(element_png)
|
cs |
다행히 셀레니움 기능중에 특정 element 값만 캡쳐하는 기능이 있었다. screenshot으로 저장하는 기능과 screenshot_as_png로 저장하는 기능인데 차이점은 거의 없는 것 같다. 이렇게 수월하게 되면 개발이 재미가 없지...
해결해야할 문제들
- 특정부분이 화면에 나오지 않으면 짤려서 찍혔다.
- 크롭옵션에 따라 캡쳐가 안 되기도 했다.
- 듀얼모니터에서 실행이 안 됐다.
- 화면 축소시 찍히지 않았다.

최대한 덜 잘려나오게 하려면 셀레니움이 노트북 화면이 아닌, 듀얼 모니터 화면에서 실행 되어야 하는데 안 됐다. 좌표값을 옮겨서 확대를 하라고 해서 여러 방법 끝에 됐다. 그리고 headless의 경우 어떤 화면에서는 잘 캡쳐가 됐지만, 안 되는 경우도 있어서 뺐다.
|
1
2
3
4
5
6
7
8
9
10
|
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
# chrome_options.headless = True #싸이트마다 다르게 캡쳐가 됨
# chrome_options.add_argument("--kiosk") #F11 눌러진 효과
chrome_options.add_argument("--window-position=2000,0") #듀얼모니터에서 보기
driver = webdriver.Chrome(options=chrome_options)
driver.maximize_window()
|
cs |
듀얼 모니터 화면에서 캡쳐가 됐다!! 하지만 화면이 잘리지 않으려면 화면을 축소해서 찍어야 했다. 사람들마다 셀레니움 화면을 축소하는 다양한 방법을 소개시켜줬는데 잘 안 됐다. 기본 설정에 들어가서 바꾸라는 사람부터 zoom out을 하라는 것도 있었지만, 값을 바꾸게 되면 css에도 영향을 미치는 것 같았다.
|
1
2
3
4
5
|
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# driver.execute_script("document.body.style.zoom='50%'")
driver.execute_script("document.body.style.transform = 'scale(0.50)'")
|
cs |
document.body.style.zoom을 활용하게 되면 안 된다. document.body.style.transform을 사용해야 한다. 원하는 요소가 한 페이지에 나오면 좋겠지만, 아닌 경우도 있으니 쓰시면 될 것 같습니다. 문제는 어느정도 해결한 듯 보였으나 원하는 이미지가 서로 다른 element에 있어서 이미지 병합까지 하게 됐다.
밑에 과정은 gsmarena에서 기본적인 정보를 크롤링하고 이미지 캡쳐, 병합하는 과정입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
from bs4 import BeautifulSoup
import pandas as pd
import requests
import re
#환율
def exchange_rate(today_rate, price,r) : #r은 반올림 자리 숫자
p_price = round(today_rate * int(price),r)
return str(p_price)
#월
def month_string_to_number(string):
m = { 'jan': 1, 'feb': 2, 'mar': 3, 'apr':4, 'may':5, 'jun':6, 'jul':7, 'aug':8, 'sep':9, 'oct':10, 'nov':11, 'dec':12 }
s = string.strip()[:3].lower()
try:
month = m[s]
return month
except:
return '확인 바람'
#이름
def crawl_gsmarena(j,today_rate1,today_rate2) :
global phone_name
url = j
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, "html.parser")
tds= soup.find_all('td', attrs={'class': 'nfo'})
try :
phone_name = soup.select('h1.specs-phone-name-title')[0].text
except :
phone_name = 0
return phone_name
for td in tds:
global s_year, s_mon, phone_price, exchange
if 'status' in str(td) :
# <td class="nfo" data-spec="status">Available. Released 2021, August 27</td>
try :
td = td.text
s_year = re.findall('\d+', td)[0]
s_mon = td.split(',')[1]
s_mon = re.sub('[^a-zA-Z]', '', s_mon)
s_mon = month_string_to_number(s_mon)
except :
s_year = 'comming_soon'
s_mon = 'comming_soon'
elif 'price' in str(td) :
td = td.text
# p = td.split()[1]
if '$' in td :
p = td.split('$')[1].split()[0]
phone_price = p
exchange = ''
elif '€' in td :
p = td.split('€')[1]
p = p.split()[0].replace(',','').split('.')[0]
phone_price = exchange_rate(today_rate1, p,2) # today_rate 환율 입력
exchange = today_rate1
elif '₹' in td :
p = td.split('₹')[1]
p = p.split()[0].replace(',','').split('.')[0]
phone_price = exchange_rate(today_rate2, p,3) # today_rate 환율 입력
exchange = today_rate2
elif 'EUR' in td :
p = td.replace(',','')
p = re.findall('\d+', p)[0]
phone_price = exchange_rate(today_rate1, p,2)
exchange = today_rate1
else :
phone_price = td
exchange = ''
return phone_name, s_year, s_mon, phone_price, exchange
|
cs |
핸드폰 이름, 생산 년도, 월, 핸드폰 가격 등을 가져옵니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import os
import glob
from PIL import Image
import glob
import shutil
#이미지 병합
def merge_img(name):
files = glob.glob('crawling_temp/*.png')
full_width, full_height = 364, 0 #364로 고정 / 너비가 2배로 찍혀서 반은 없애야 함
for f in files :
image = Image.open(f)
_, height = image.size
# full_width = max(full_width,width)
full_height += height
canvas = Image.new('RGB', (full_width, full_height), 'white')
output_height = 0
for i in files:
with Image.open(i) as image :
_, height = image.size
canvas.paste(image, (0, output_height))
output_height += height
canvas.save(f'crawling/{name}.png')
shutil.rmtree('crawling_temp')
return
#이미지 리사이징
def resize_img():
im = Image.open(f'crawling_temp/a.png')
half = 0.5
out = im.resize( [int(half * s) for s in im.size] )
out.save(f'crawling_temp/a.png')
im.close()
return
chrome_options = Options()
chrome_options.add_argument('--profile-directory=Default')
chrome_options.add_argument("--incognito")
chrome_options.add_argument("--disable-plugins-discovery")
chrome_options.add_argument("--window-position=2000,0") #듀얼모니터에서 보기
driver = webdriver.Chrome(options=chrome_options)
driver.maximize_window()
urls = 'https://www.gsmarena.com/samsung_galaxy_s21_fe_5g-10954.php' # 찾고자 하는 url 리스트
names = 'samsung galaxy s21' # 검색키워드 리스트
for i in range(len(urls)) :
url = urls[i]
driver.get(url)
element = driver.find_element_by_class_name("article-info")
if os.path.exists('crawling_temp') :
pass
else :
os.mkdir('crawling_temp')
element.screenshot(f'crawling_temp/a.png')
resize_img()
driver.execute_script("document.body.style.transform = 'scale(0.50)'") #축소
element2 = driver.find_element_by_id('specs-list')
element2.screenshot(f'crawling_temp/b.png')
name = names[i]
if '/' in name :
name = name.replace('/','')
merge_img(name)
time.sleep(2) # 빠르면 봇으로 인식
# 이미 사용중이라고 에러가 뜨면 vs코드 껐다가 다시 실행
print('완료')
|
cs |
이미지 병합, 리사이징까지의 과정이 있습니다. 화면을 축소하니까 사진을 잘못 찍는 경우가 있어서, 사진 1장은 원래 크기에서 찍고, 다른 1장은 축소해서 찍었네요. 그리고 리사이징을 해서 병합하는 복잡한 과정을 거쳤습니다. 여러분들이 도전하는 크롤링과 자동 캡쳐 스크린샷 코드는 문제가 없길 바랍니다 ㅠㅠ
'할 수 있다. 파이썬' 카테고리의 다른 글
| (5) 효율 100% 엑셀 사무 자동화, 함수 및 기능들 총정리 (파이썬, 판다스) (0) | 2022.01.23 |
|---|---|
| (4) 실무 엑셀 함수 TOP3 자동화 - VLOOKUP 다중조건, INDEX/MATCH 파이썬으로 (0) | 2022.01.22 |
| (3) 실무 엑셀 함수 VLOOKUP, INDEX MATCH 시간 50배 단축, 파이썬으로 한 방에 잡자 (0) | 2022.01.21 |
| (2) 파이썬 엑셀 사무 자동화 : 보안 걸린 엑셀 한 번에 뚫기 openpyxl? xlwings? (2) | 2022.01.20 |
| (1) 파이썬 엑셀 사무 자동화 : 회사 사내망 때문에 좌절한 당신... (0) | 2022.01.19 |



