목차 (작성 예정)
(1) 100% 만족할 파이썬 엑셀 사무 자동화, 회사에서 안 된다면?
(3) 시간 50배 단축, 실무 엑셀 함수 구현 (vlookup, index match 등)
(5) 엑셀 실무용 유용한 함수 및 기능들 파이썬으로 해결
(6) 언제까지 수작업할래? 크롤링과 사진 자동으로 캡쳐, 스샷
https://0goodmorning.tistory.com/72
지난 편에 이어서 작성하겠습니다. 실무에서 자주 활용되는 엑셀 함수 VLOOKUP, INDEX/MATCH 기본적인 구현 방법에 대해서는 전 글을 확인해주세요^^
|
1
2
3
4
5
6
7
8
9
10
11
|
import pandas as pd # pandas가 없으면 터미널에서 pip install pandas
# df = pd.read_csv('위치/파일명.csv', encoding='utf-8-sig') # 직접 불러오기
df = pd.read_clipboard(keep_default_na=False, sep="\t") # 복사해서 불러오기
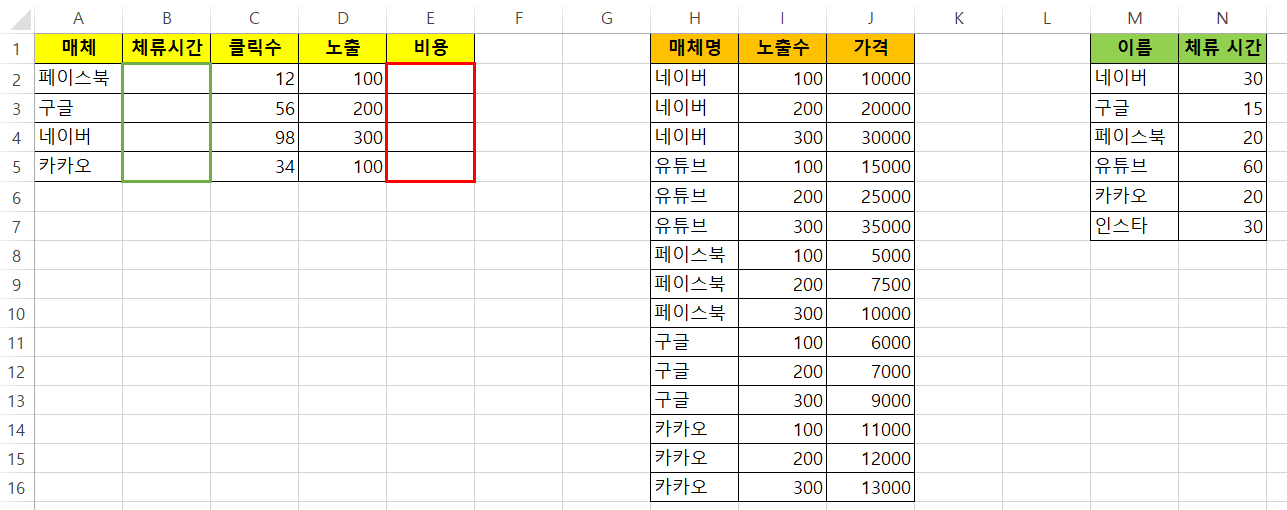
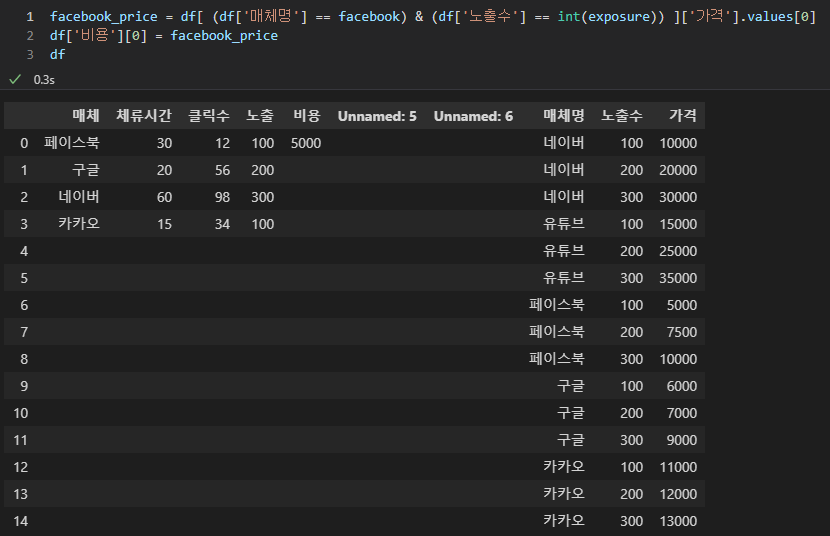
for i in range(4) : #시트를 분리하지 않았기 때문에 매체 4개 값만
col_A = df['매체'][i]
col_D = df['노출'][i]
col_E = df[ (df['매체명'] == col_A) & (df['노출수'] == col_D) ]['가격'].values[0]
df['비용'][i] = col_E
|
cs |

저번처럼 모듈을 불러오고 반복문을 사용합니다. 지난번에는 facebook, exposure라고 변수명을 지정했는데, 이번에는 간편하게 col_A, col_D 라고 지정하겠습니다. 지난 내용을 단지 for 문 안에 집어넣은 것이기 때문에 어려움은 없지만, 파이썬을 아예 처음 접하신 분들을 위해서 잠깐 설명을 하자면

값이 4개 밖에 되지 않아서 직접 쳐도 된다고 생각하지만, 저희가 다루는 데이터 양이 많습니다. 그래서 이를 반복문으로 돌리는 것입니다. for문의 기본 구조를 보자면,
for [변수] in [문자열, 리스트, 튜플] :
[수행부분]
이런 식으로 구성이 되어 있는데, [문자열, 리스트, 튜플] 등을 순서대로 돌면서 [변수]에 넣어주게 됩니다. range(4)를 할 경우에 [변수]에 0,1,2,3 까지를 넣어주게 됩니다. range의 경우 0부터 시작해서 range 안에 숫자-1 까지의 숫자를 사용합니다.
col_A = df['매체'][i] 는 for문을 돌면서 변수가 0 일 때 페이스북, 1 일 때 구글, 2 일 때 네이버... 이런 식으로 변경이 되는 것입니다. 몇 번 사용하시다 보면 자연스레 익히게 됩니다. 어떤 식으로 돌아가는지만 생각하시면 될 것 같네요.

만약 페이스북의 노출이 400이 되면 어떻게 될까요? 엑셀에서도 #N/A 값이라고 하면서 오류가 뜹니다. 파이썬에서도 위와 같은 코드로 진행할 경우 마찬가지로 오류가 뜨게 됩니다.

이렇게 오류가 뜨게 되는 이유는 매체명이 페이스북이면서, 노출수가 400인 케이스가 존재하지 않기 때문입니다. 그런데 .values[0]으로 값을 가져오라고 해서 index 0 is out of bounds가 뜨게 되는 것입니다. 이 오류를 해결하기 위해서는 간단하게 한 줄만 추가하면 됩니다.
|
1
2
3
4
5
6
7
|
for i in range(4) : #시트를 분리하지 않았기 때문에 매체 4개 값만
col_A = df['매체'][i]
col_D = df['노출'][i]
col_E = df[ (df['매체명'] == col_A) & (df['노출수'] == int(col_D)) ]['가격']
if len(col_E) : #존재하는지 확인
df['비용'][i] = col_E.values[0]
|
cs |

len() 함수는 문자열의 길이를 구하는 함수인데, 아무것도 존재하지 않을 때 0 이 된다. 그리고 파이썬에서 0은 False로 인식하기 때문에, len(col_E)가 0이 되면 if 문이 실행이 되지 않는다. 그렇기 때문에 페이스북의 비용은 빈칸이 된 것이다. 그렇다면 페이스북 비용에 다른 값을 넣고 싶다면 어떻게 해야할까?
|
1
2
3
4
5
6
7
8
9
10
|
for i in range(4) : #시트를 분리하지 않았기 때문에 매체 4개 값만
col_A = df['매체'][i]
col_D = df['노출'][i]
col_E = df[ (df['매체명'] == col_A) & (df['노출수'] == col_D) ]['가격']
if len(col_E) :
df['비용'][i] = col_E.values[0]
else :
df['비용'][i] = '비용 확인바람'
|
cs |

else 구문을 활용하여 쉽게 자신이 원하는 문구를 집어넣을 수 있다. 파이썬을 많이 이용하신 분들에게는 완전 쌩기초기 때문에 그냥 웃으면서 넘기시면 됩니다. 이제 어느정도 활용을 해봤으니, 다른 시트에서 값을 가져오는 방법을 소개하고자 합니다.

파일을 불러오는 방식은 처음과 동일합니다. 다만 차이는 데이터를 한 번에 불러오지 않고, 나눠서 불러오는 것입니다. df를 쓰려다가 이해하기 쉽게 sheet1과 sheet2로 데이터를 읽었습니다.
|
1
2
3
4
5
6
7
8
9
10
|
for i in range(len(sheet1)) : #시트를 분리했기 때문에 sheet1의 길이만큼 len()
col_A = sheet1['매체'][i]
col_D = sheet1['노출'][i]
col_E = sheet2[ (sheet2['매체명'] == col_A) & (sheet2['노출수'] == int(col_D)) ]['가격']
if len(col_E) :
sheet1['비용'][i] = col_E.values[0]
else :
sheet1['비용'][i] = '비용 확인바람'
|
cs |

이전 코드와 달라진 부분이 뭘까요?
df에서 sheet1으로 바뀐 부분과 어떤건 sheet2로 바뀌었습니다. 차이가 무엇일까 살펴보면, 우리가 비교하려는 값은 sheet1에서 뽑아줍니다. 그리고 비교하려는 값으로 얻는 것은 sheet2에서 찾기 때문에 col_E (원하는 것 = 원하는 매체 노출수에 따른 '가격')는 sheet2에서 조건을 걸게 된 것입니다.
그리고 우리는 sheet1 '비용' 컬럼을 채워야하기 때문에 sheet1['비용'][i]에 sheet2에서 받아온 '가격'을 입력하게 됩니다. 애초에 두 시트의 컬럼명이 '가격'이었으면 덜 헷갈렸을 수도 있는데, 어떤 부분을 체크해야하는지 알려드리기 위해서 일부러 다르게 사용했습니다. 코드는 작업하기 편하게 사용하시면 됩니다.
데이터가 몇개 되지 않으면 INDEX/MATCH 함수나 VLOOKUP 함수를 엑셀에서 돌려도 시간이 얼마 안 걸립니다. 하지만 데이터가 많아지면 많아질수록 웬만한 사무용 컴퓨터에서는 엑셀이 버벅입니다. 조금이라도 도움이 되셨으면 좋겠고 다음에는 엑셀을 파이썬으로 구현할 때 사용했던 기능들에 대해서 소개하겠습니다.
'할 수 있다. 파이썬' 카테고리의 다른 글
| (6) 사무 자동화 - 웹 검색 후 특정 부분 자동 캡쳐/ 스크린샷, 확대 축소 (0) | 2022.01.24 |
|---|---|
| (5) 효율 100% 엑셀 사무 자동화, 함수 및 기능들 총정리 (파이썬, 판다스) (0) | 2022.01.23 |
| (3) 실무 엑셀 함수 VLOOKUP, INDEX MATCH 시간 50배 단축, 파이썬으로 한 방에 잡자 (0) | 2022.01.21 |
| (2) 파이썬 엑셀 사무 자동화 : 보안 걸린 엑셀 한 번에 뚫기 openpyxl? xlwings? (3) | 2022.01.20 |
| (1) 파이썬 엑셀 사무 자동화 : 회사 사내망 때문에 좌절한 당신... (0) | 2022.01.19 |