목차
KoGPT2로 슬로건, 광고문구를 생성하고 이를 어떻게 개선할 것인가에 대해서 이어서 작성하겠습니다. 처음에 포스팅 하나에 넣으려고 했는데 생각보다 길어져서 나눴습니다. 이번 포스팅은 아웃풋과 인풋을 어떻게 조정했는지에 대해서 쓰겠습니다.
짧은 텍스트 / 문장 유사도 찾기

사용 이유 와 목적 : 인풋 데이터에 '금융'과 관련된 설명을 넣었는데, 갑자기 '좋은 일자리 만들어주세요'라는 문구가 뜬금없이 튀어나오게 된다. 데이터가 충분하면 이런 일이 없겠지만 추가로 모을 수는 없어서.. 이러한 결과값들을 최대한 배제하는 방법에 대해서 생각했다.
- TF-IDF, CNN을 활용을 활용한 슬로건 분류
- Word2Vec을 사용해서 자주 등장하는 단어와 유사한 값을 지닌 단어가 포함된 문장을 노출
- 문장 유사도 (키워드, 요약, sentence transformer)

4-3 파이썬 팀프로젝트 CNN 카테고리 분류 모델 학습 및 평가
네 번째 프로젝트 1. 간단한 intro 2. 웹 크롤링 및 전처리 3. 모델 학습 및 평가 프로젝트를 하면서 느낀 보완사항은 : -데이터의 길이가 너무 짧으면 단어를 추출하는데 한계가 있고, 과적합이 발
0goodmorning.tistory.com
TF-IDF, CNN 카테고리 분류
슬로건, 광고문구에 인풋 값과 관련 없는 결과가 나올 확률은 크지 않기 때문에(이후에 보여드립니다), 카테고리(y)와 슬로건(x)을 학습시켜서 모델링을 해봤다.(이전 코드 참고)
하지만 아무리 수정을 해도 CNN 모델의 성능은 좋아지지 않았다. 40% 정확도가 최선으로 나왔는데, 이를 생각해보면 카테고리와 슬로건의 상관관계가 거의 않아서 정확도 개선이 되지 않는 것으로 보인다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from konlpy.tag import Kkma
import collections
slogan_list2 = []
for slogan in slogan_list :
kkma = Kkma()
slogan_ = kkma.nouns(slogan)
slogan_list2.append(slogan_)
#중첩 리스트 제거
list_removed = sum(slogan_list2, [])
#단어 카운팅
dict={}
dict=collections.Counter(list_removed)
dict = sorted(dict.items(), key=lambda x: x[1], reverse=True)
#print(dict)
#가장 많이 나오는
keyword = next(iter(dict))[0] #사전 첫번째 단어
print(keyword)
|
cs |
꼬꼬마로 형태소 분류를 해서 가장 자주 나오는 명사들의 개수를 카운팅하고, 단어 : 개수를 딕셔너리로 만든다.
|
1
2
3
4
5
6
7
|
from gensim.models import Word2Vec
model = Word2Vec(slogan_list2, vector_size=100, window=4,
min_count=2, workers=4, epochs=50, sg=1)
#가장 많이 나오는 단어와 유사한 단어
model.wv.most_similar(keyword,topn=10)
|
cs |

결과값을 확인 했을 때, 나쁘지 않게 나왔지만.. 이 단어들로이 포함되지 않는 문구를 필터링한다면, 걸러져야할 광고문구보다 괜찮은 광고문구들도 대부분 걸러질 것으로 보여서 다른 방법을 또 고민했다.
텍스트 유사도를 구할 때, 추천 시스템에서 사용했던 TF-IDF, 코사인 유사도를 사용하려고 했다. 하지만 파이널 프로젝트에는 적용하기 힘들었던 이유가 비교할 문장이 길지 않고, 한 문장으로 이루어졌기 때문이다. 프로젝트가 끝나고 현재 Textrank나 문장 요약, 키워드 추출 등을 공부하고 있는데, 이 방법도 적합하지 않은 방법이었다.

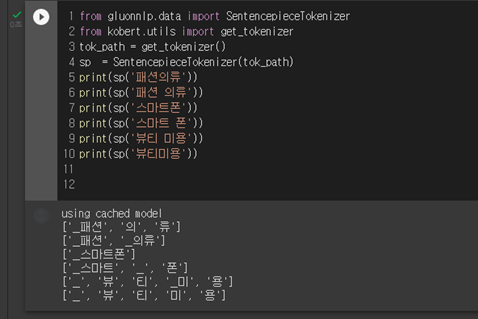
그래서 찾게 된 것이 Sentence Transformer다. 그런데 생각보다 구글에는 예시가 많지 않았다. 영어 모델은 유사도 높게 나왔는데, 한글의 경우 위의 사진처럼 '한 남자가'라는 단어가 일치한다고 유사도 94퍼센트가 나오는 아이러니한 현상이 발견됐다. 구글링을 더 하다가 Ko-Sentence-BERT-SKTBERT 모델이 나왔는데 오류 때문에 잘 되지 않았다.
Pretrained Models — Sentence-Transformers documentation
We provide various pre-trained models. Using these models is easy: Multi-Lingual Models The following models generate aligned vector spaces, i.e., similar inputs in different languages are mapped close in vector space. You do not need to specify the input
www.sbert.net

더 검색하다가 발견한 모델! 유사도가 SKTBERT에서 테스트한 예제들과 결과가 비슷하게 나와서 사용하기로 했다.

결과가 좋다! 그리고 예상했던대로 인풋데이터와 관련이 없는 결과(슬로건, 광고문구)는 다른 문구들과 비교했을 때 전체적으로 유사도가 높지 않음을 확인할 수 있다. / RPG 게임에 웬 패션 스타일인가?
하지만 여기서도 또 문제 아닌 문제가 생겼다. 필터링 되는 슬로건 중에서도 키워드만 바꾸면 괜찮아보이는 슬로건들이 있다. 그래서 이걸 살리는 것도 좋지 않겠냐는 멘토님의 말씀이 있어서.. 사용자가 직접 민감도를 설정해 필터링의 할 수 있는 기능을 추가했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
#문장 유사도
#개별 추출
from sentence_transformers import SentenceTransformer, util
import numpy as np
import random
import pandas as pd
#모델 불러오기
model = SentenceTransformer('distiluse-base-multilingual-cased-v1')
#회사 리스트
company = pd.read_csv('datasets\company_list.csv')
company_list = company.company.values.tolist() #회사명을 리스트로
#비교할 슬로건 선택
no_sim_list = [] #관련 없는 슬로건 추출
total_slogan = [] #슬로건 전체를 담는 리스트 / 중첩리스트용
n = 0
try : #n이 증가하지 않을 경우 무한루프?
while n < 5 :
#유사도 비교할 리스트
corpus = kor_list
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
#유사도 비교할 문장
query = random.sample(kor_list, 1)
print("Query : ", query)
#코사인 유사도 사용하여 5개 유사한 슬로건 찾기
top_k = 6 #query 포함 top 5개
query_embedding = model.encode(query, convert_to_tensor=True)
cos_scores = util.pytorch_cos_sim(query_embedding, corpus_embeddings)[0]
cos_scores = cos_scores.cpu()
top_results = np.argpartition(-cos_scores, range(top_k))[0:top_k] # np 사용 이유 : 순위를 순서대로 맞추기 위함
#민감도 비교하기 위한 유사도 더하기
sum = 0
for idx in top_results[1:top_k]:
sum += cos_scores[idx]
f_sum = float(sum)/5 #tensor to float
print(f_sum)
#사용자 인풋 민감도 비교
sim_list = [] #유사 슬로건 담을 리스트
sim_list2 = [] #수정된 슬로건 담을 리스트
if f_sum >= input_sim / 100 :
for idx in top_results[0:top_k-1]:
copy_ = corpus[idx].strip()
sim_list.append(copy_)
print(sim_list)
sim_list2 = sim_list
for i in range(len(sim_list2)) :
for c in company_list :
if c in sim_list2[i] :
sim_list2[i] = sim_list2[i].replace(c,'*'*len(c))
total_slogan.append(sim_list2)
kor_list = differ_sets(kor_list, sim_list)
n += 1
#print(len(kor_list))
else :
no_sim_list.append(query)
kor_list = differ_sets(kor_list, query) #kor_list에서 query를 제거
print('관련이 없는 슬로건 데이터 추가')
except :
print('데이터가 부족합니다.')
print('완료')
#print(no_sim_list)
print(total_slogan)
|
cs |
우선 슬로건 문구를 포함한 리스트에서 영어로만 이뤄진 슬로건을 제외해 kor_list를 만들었다. 영어가 포함된 문장의 경우 유사도가 얼추 비슷하게 나왔는데, 영어로만 이루어진 문장은 문장 유사도 성능이 떨어져서 아예 제외시켰다. 이후 한 개를 랜덤으로 뽑아서 유사도가 비슷한 값 5개를 뽑아서 평균을 냈을 때, input_sim과 크기를 비교해서 살릴지 버릴지 고민을 했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#차집합 함수
def differ_sets(a,b) :
lst = list(set(a)-set(b))
return lst
#영어 슬로건 따로 추출
import re
eng_list = []
for slogan in slogan_list :
slogan_ = re.sub('[^A-Za-z가-힣]', '',slogan) #영어 한글만 남기기
slogan_ = re.sub('[^가-힣]',' ', slogan_) #영어는 공백으로 남긴다
if slogan_.isspace(): #isalpha()는 영어 또는 한글 유무를 찾아서 안 됨
eng_list.append(slogan)
print(eng_list)
#차집합
kor_list = differ_sets(slogan_list, eng_list) #한국 슬로건만 있는 리스트
|
cs |
영어로만 이루어진 문장을 뽑는데 애를 먹었다. isalpha()를 사용하게 되면 영어로만 이루어진게 아니라, 한글이 있을 때도 True를 반환하기 때문에 다른 방법을 사용해야했다. 우선 공백을 없애고, 한글만을 남게한다. 만약 영어로만 이루어졌으면 isspace()함수에서 True를 반환하기 때문에 영어만 포함된 문장을 뽑을 수 있다. 반대로 한글로만 이뤄진 문장이 필요하면 '^가-힣' 대신 '^A-Za-z'을 활용하면 된다.

|
1
2
3
4
5
6
7
8
9
10
11
|
company_list = company.company.values.tolist()
len(company_list)
for c in company_list :
for i in range(len(total_slogan) :
if c in total_slogan[i] :
# print(c)
slogan_edit = total_slogan[i].replace(c,'*'*len(c))
# print('수정')
slogan_edit
|
cs |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
"""
** 가이드 **
-input_sim
0~15 : 가장 자유로움
15~30 : 자유로움
30~45 : 조금씩 걸러짐
45~60 : 많이 걸러짐 / 강제로 기업 설명을 인식시켜서 더 제한적인 슬로건
60~ : 거의 다 걸러짐 / 슬로건 100개를 했을 경우 유사율 평균 70 이상은 거의 없음
-input_text
최대한 명사 위주의 설명
영어를 쓸경우 뒤에 나오는 단어와 붙여쓰면 더 좋은 결과 ex) 'LED 마스크'보다는 'LED마스크'
"""
input_sim = 40 # input data 유사성 민감도 지정 / 숫자가 작을수록 관련 없는게 나올 확률이 커짐 / 최소 50이상 설정
input_text = '커피전문기업'
input_text_list = input_text.split(' ') # input data 띄어쓰기로 나누기
eng_text = re.sub('[^a-zA-z]',' ',input_text).strip()
kkma = Kkma() #꼬마를 작용시 분모가 중복 되는 경우가 생김, 이를 제거해야 함
copy=[]
for txt in input_text_list :
txt_ = kkma.nouns(txt)
# print(txt_)
if len(txt_) > 1 : #(명사가 쪼개졌을 경우)
max_string = max(txt_, key=len) #가장 긴 값을 제거 (중복값)
txt_.remove(max_string)
copy += txt_
# print(copy)
if len(copy) >3 :
del_list = []
for i in range(math.ceil(len(copy)-2)) :
overlap_txt = ''.join((itemgetter(i,i+2)(copy))) # abc를 kkma로 쪼갤 경우 => a, ab, abc, b, c => abc 제거 => ab를 제거하는 과정
if overlap_txt in copy :
del_list.append(overlap_txt)
#print(del_list)
[i for i in del_list if not i in copy or copy.remove(i)] #차집합인데 순서가 안 바뀜
text = ' '.join(copy)
if input_sim > 45 :
text += ',' #,를 넣을 경우 강제로 기업설명으로 인식시켜서 조금 더 제한적인 슬로건 등장
#영어 슬로건이 포함 된 경우 초기상태로
if eng_text :
if eng_text in input_text :
text = input_text
print(text)
|
cs |
'도전하자. 프로젝트' 카테고리의 다른 글
| 6-5 파이널 프로젝트 웹 배포 : AWS, 구글 애즈 홍보, GA(구글애널리틱스) (0) | 2021.09.09 |
|---|---|
| 6-3 파이널프로젝트 KoGPT2와 짧은 텍스트/문장 유사도 (1) (0) | 2021.09.03 |
| 6-2 파이널프로젝트 나무위키, 네이버 블로그 크롤링 및 전처리 (4) | 2021.09.02 |
| 6-1 파이널 프로젝트 : 자연어처리, kogpt2를 이용한 슬로건 생성 (0) | 2021.08.26 |
| 5-3 파이썬 팀프로젝트 PyQt5로 간단 GUI 프로그램 만들기 (자동완성 기능) (2) | 2021.08.14 |